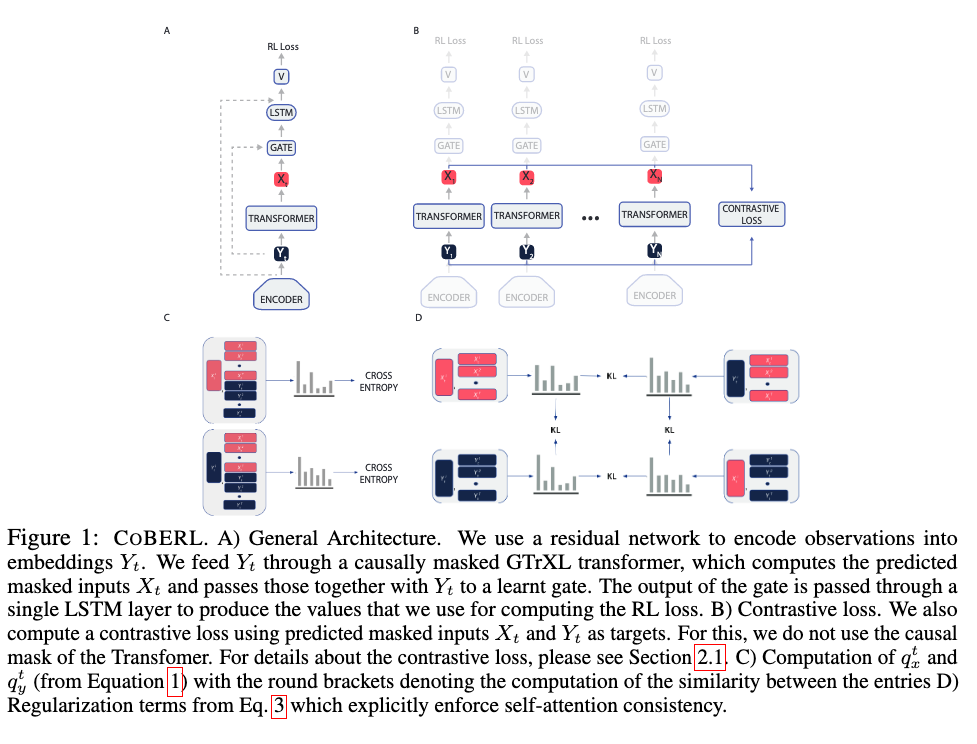
Andrea_banino Coberl Contrastive Bert for Reinforcement Learning 2022
[TOC] Title: CoBERL Contrastive BERT for Reinforcement Learning Author: Andrea Banino et. al. DeepMind Publish Year: Feb 2022 Review Date: Wed, Oct 5, 2022 Summary of paper https://arxiv.org/pdf/2107.05431.pdf Motivation Contribution Some key terms Representation learning in reinforcement learning motivation: if state information could be effectively extracted from raw observations it may then be possible to learn from there as fast as from states. however, given the often sparse reward signal coming from the environment, learning representations in RL has to be achieved with little to no supervision. approach types class 1: auxiliary self-supervised losses to accelerate the learning speed in model-free RL algorithm class 2: learn a world model and use this to collect imagined rollouts, which then act as extra data to train the RL algorithm reducing the samples required from the environment CoBERL is in class 1 it uses both masked language modelling and contrastive learning RL using BERT architecture – RELIC ...