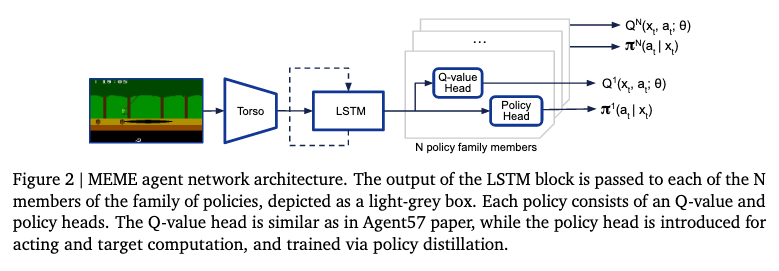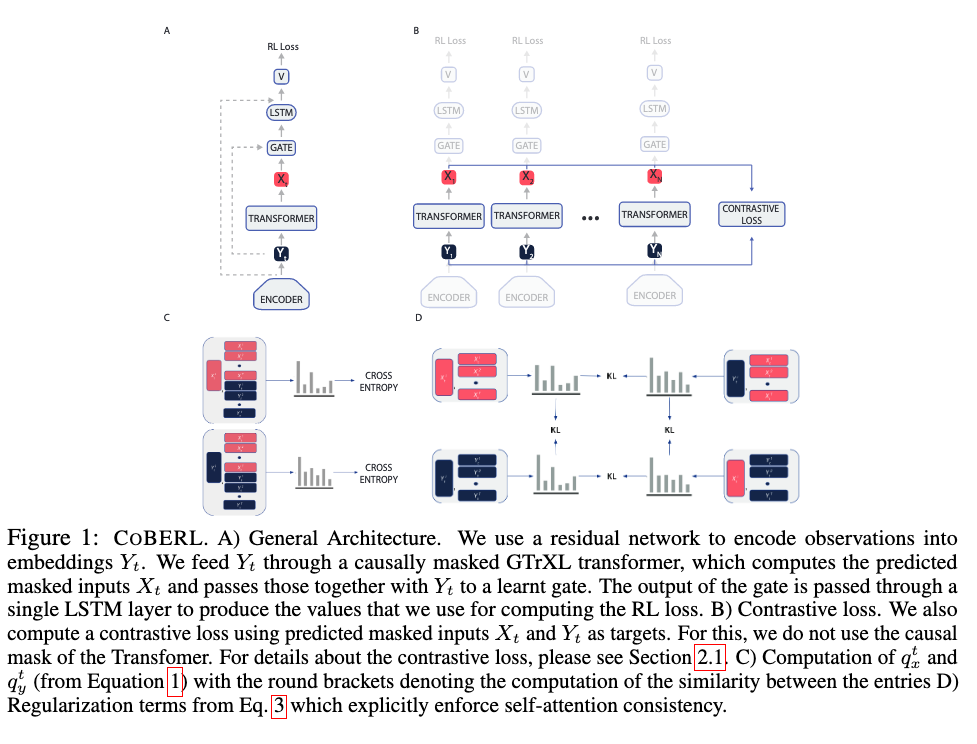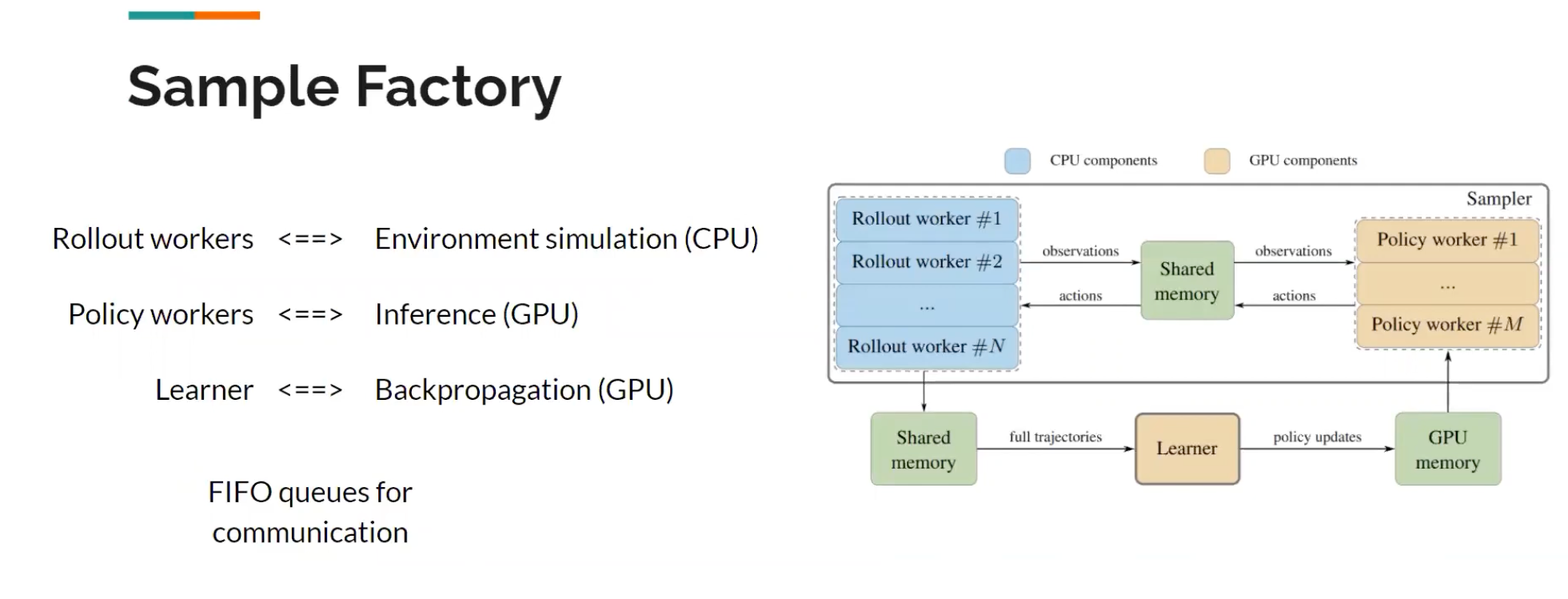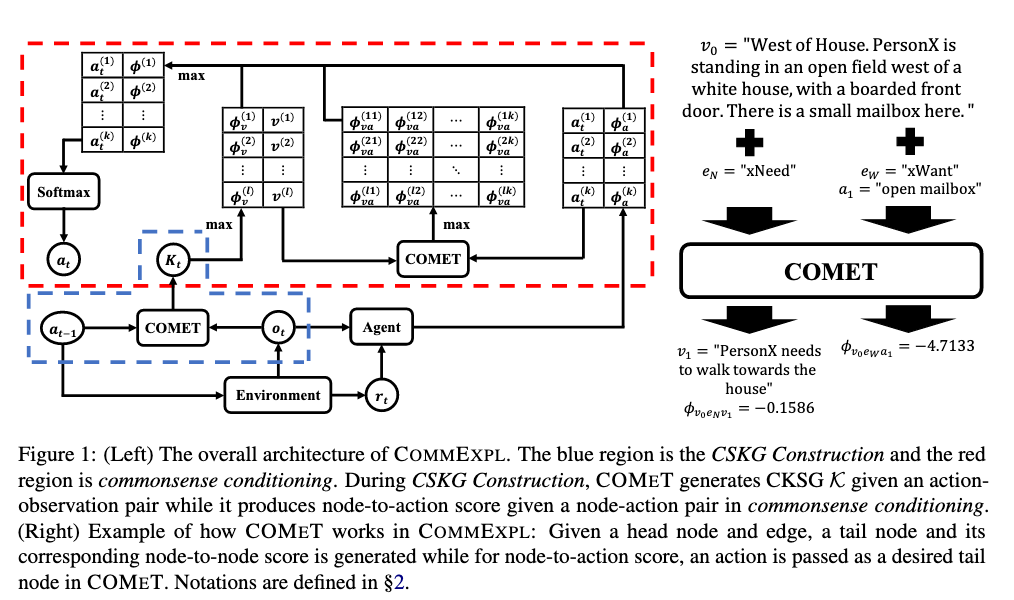
Jacob_andreas Language Models as Agent Models 2022
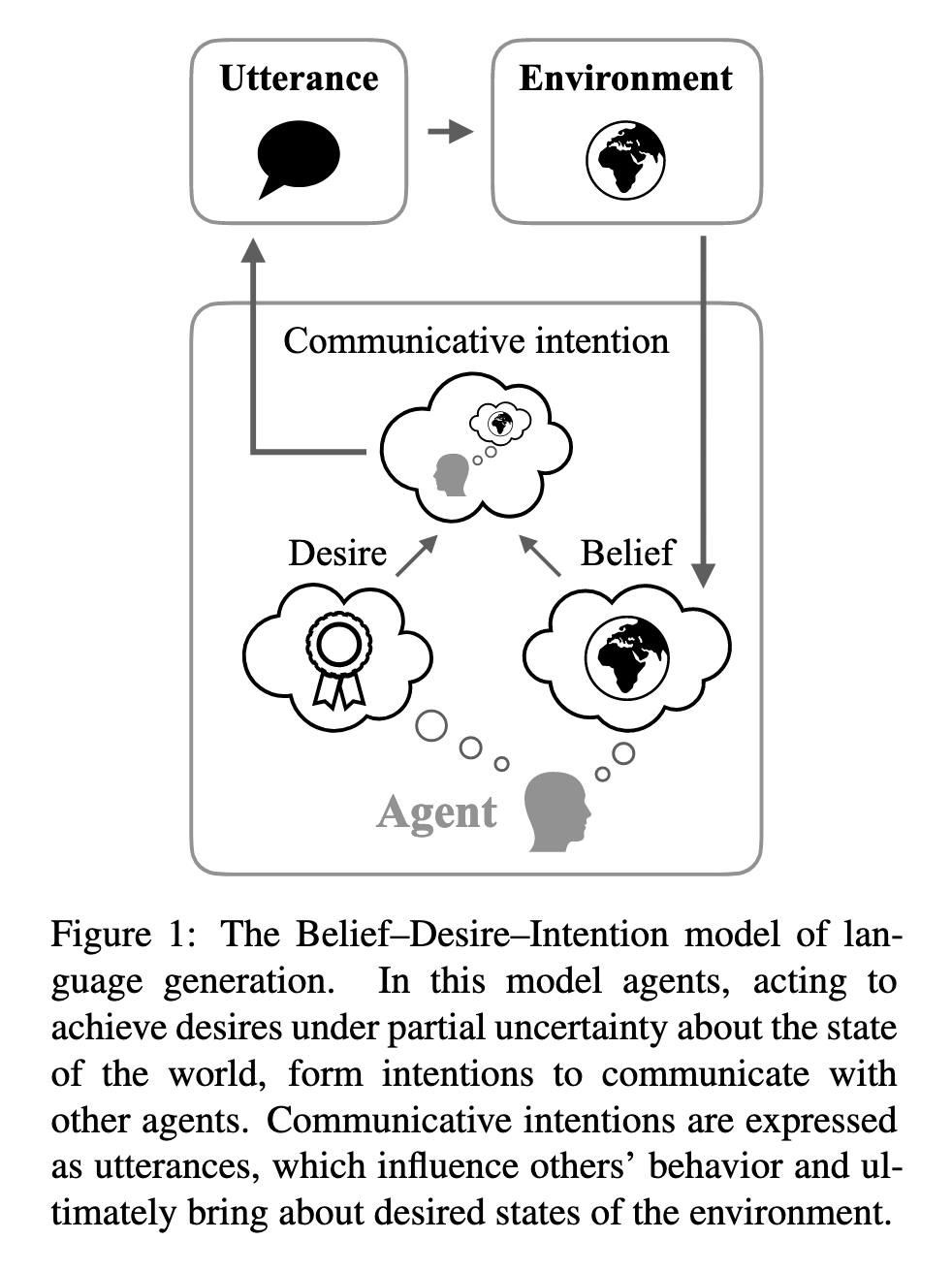
[TOC] Title: Language Models as Agent Models Author: Jacob Andreas Publish Year: 3 Dec 2022 Review Date: Sat, Dec 10, 2022 https://arxiv.org/pdf/2212.01681.pdf Summary of paper Motivation during training, LMs have access only to the text of the documents, with no direct evidence of the internal states of the human agent that produce them. (kind of hidden MDP thing) this is a fact often used to argue that LMs are incapable of modelling goal-directed aspects of human language production and comprehension. The author stated that even in today’s non-robust and error-prone models – LM infer and use representations of fine-grained communicative intensions and more abstract beliefs and goals. Despite that limited nature of their training data, they can thus serve as building blocks for systems that communicate and act intentionally. In other words, the author said that language model can be used to communicate intention of human agent, and hence it can be treated as a agent model. Contribution the author claimed that in the course of performing next-word prediction in context, current LMs sometimes infer inappropriate, partial representations of beliefs ,desires and intentions possessed by the agent that produced the context, and other agents mentioned within it. Once these representations are inferred, they are causally linked to LM prediction, and thus bear the same relation to generated text that an intentional agent’s state bears to its communicative actions. The high-level goals of this paper are twofold: first, to outline a specific sense in which idealised language models can function as models of agent belief, desires and intentions; second, to highlight a few cases in which existing models appear to approach this idealization (and describe the ways in which they still fall short) Training on text alone produces ready-made models of the map from agent states to text; these models offer a starting point for language processing systems that communicate intentionally. Some key terms Current language model is bad ...