Timo_schick Toolformer Language Models Can Teach Themselves to Use Tools 2023
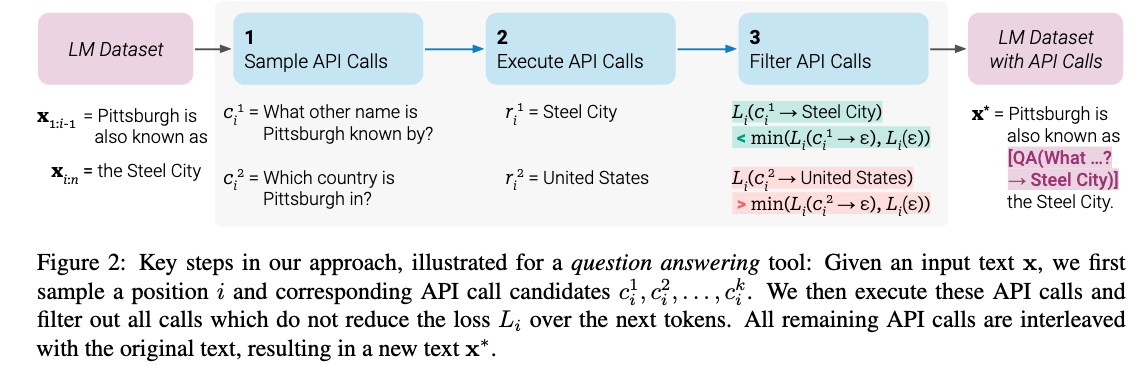
[TOC] Title: Toolformer: Language Models Can Teach Themselves to Use Tools 2023 Author: Timo Schick et. al. META AI research Publish Year: 9 Feb 2023 Review Date: Wed, Mar 1, 2023 url: https://arxiv.org/pdf/2302.04761.pdf Summary of paper Motivation LMs exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also struggle with basic functionality, such as arithmetic or factual lookup. Contribution In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model that incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system and a calendar. Some key terms limitation of language models ...