[TOC]
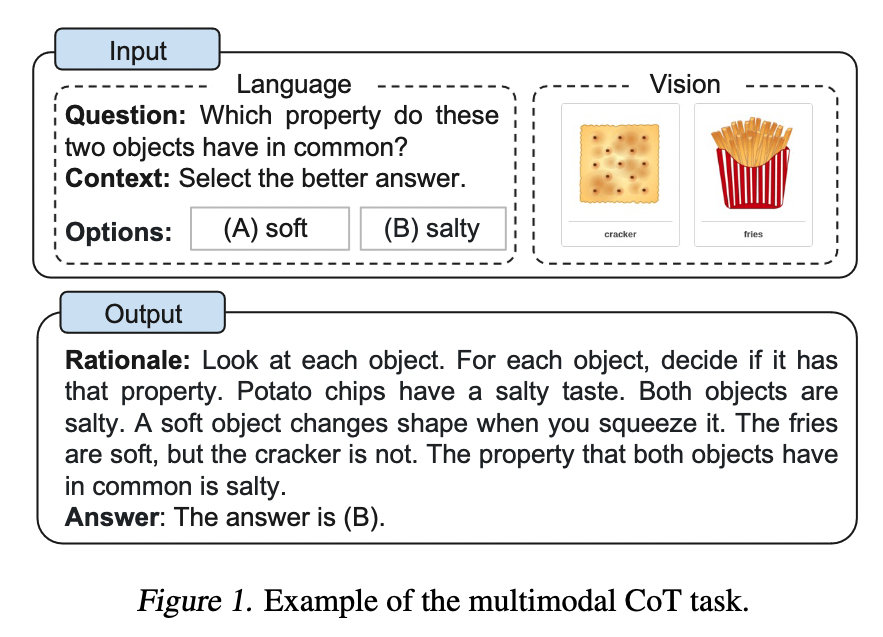
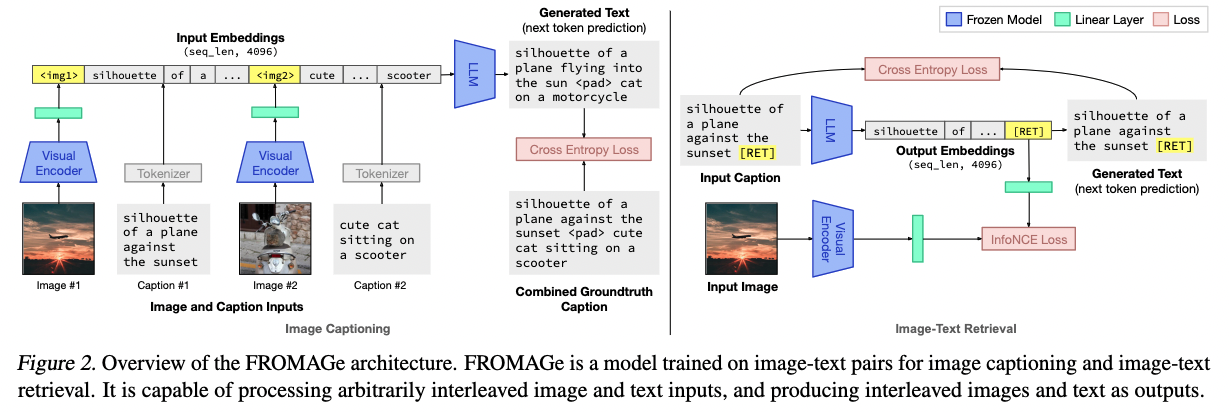
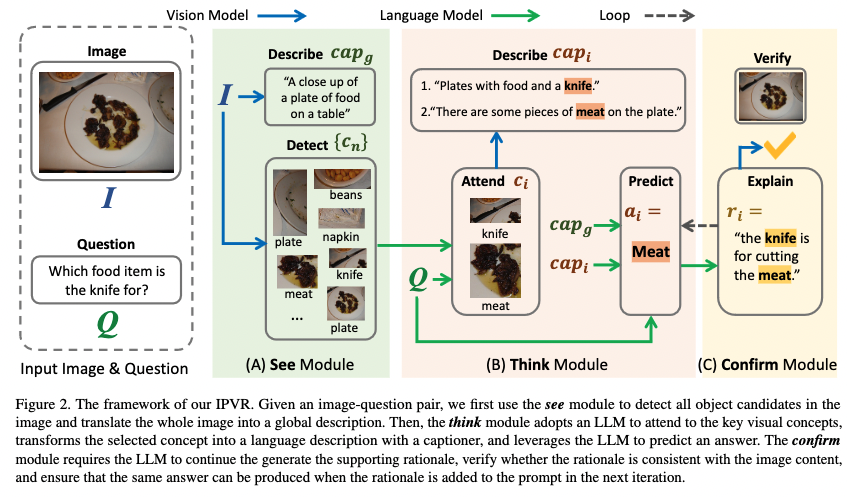
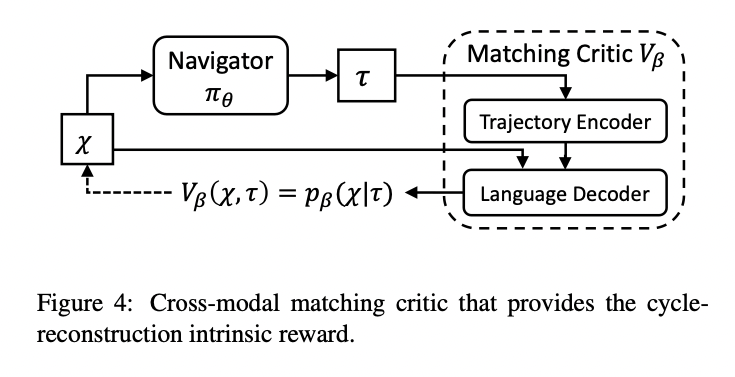
Title: See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge Based Visual Reasoning Author: Zhenfang Chen et. al. Publish Year: 12 Jan 2023 Review Date: Mon, Feb 6, 2023 url: https://arxiv.org/pdf/2301.05226.pdf Summary of paper Motivation Solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect external world knowledge, and perform step-by-step reasoning to answer the questions correctly. Contribution We propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge based visual reasoning. IPVR contains three stages, see, think, and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rational to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. Some key terms human process to handle knowledge-based visual reasoning
...