Junnan_li Blip2 Boostrapping Language Image Pretraining 2023
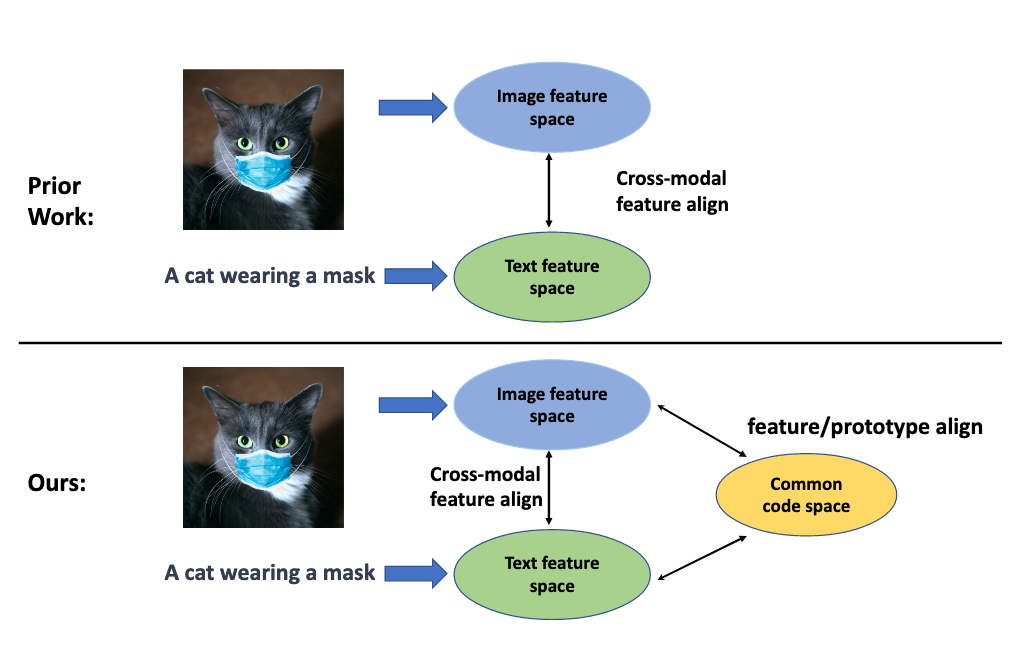
[TOC] Title: BLIP2 - Boostrapping Language Image Pretraining 2023 Author: Junnan Li et. al. Publish Year: 15 Jun 2023 Review Date: Mon, Aug 28, 2023 url: https://arxiv.org/pdf/2301.12597.pdf Summary of paper The paper titled “BLIP-2” proposes a new and efficient pre-training strategy for vision-and-language models. The cost of training such models has been increasingly prohibitive due to the large scale of the models. BLIP-2 aims to address this issue by leveraging off-the-shelf, pre-trained image encoders and large language models (LLMs) that are kept frozen during the pre-training process. ...