Yecheng Jason Ma Eureka Human Level Reward Design via Coding Large Language Models 2023
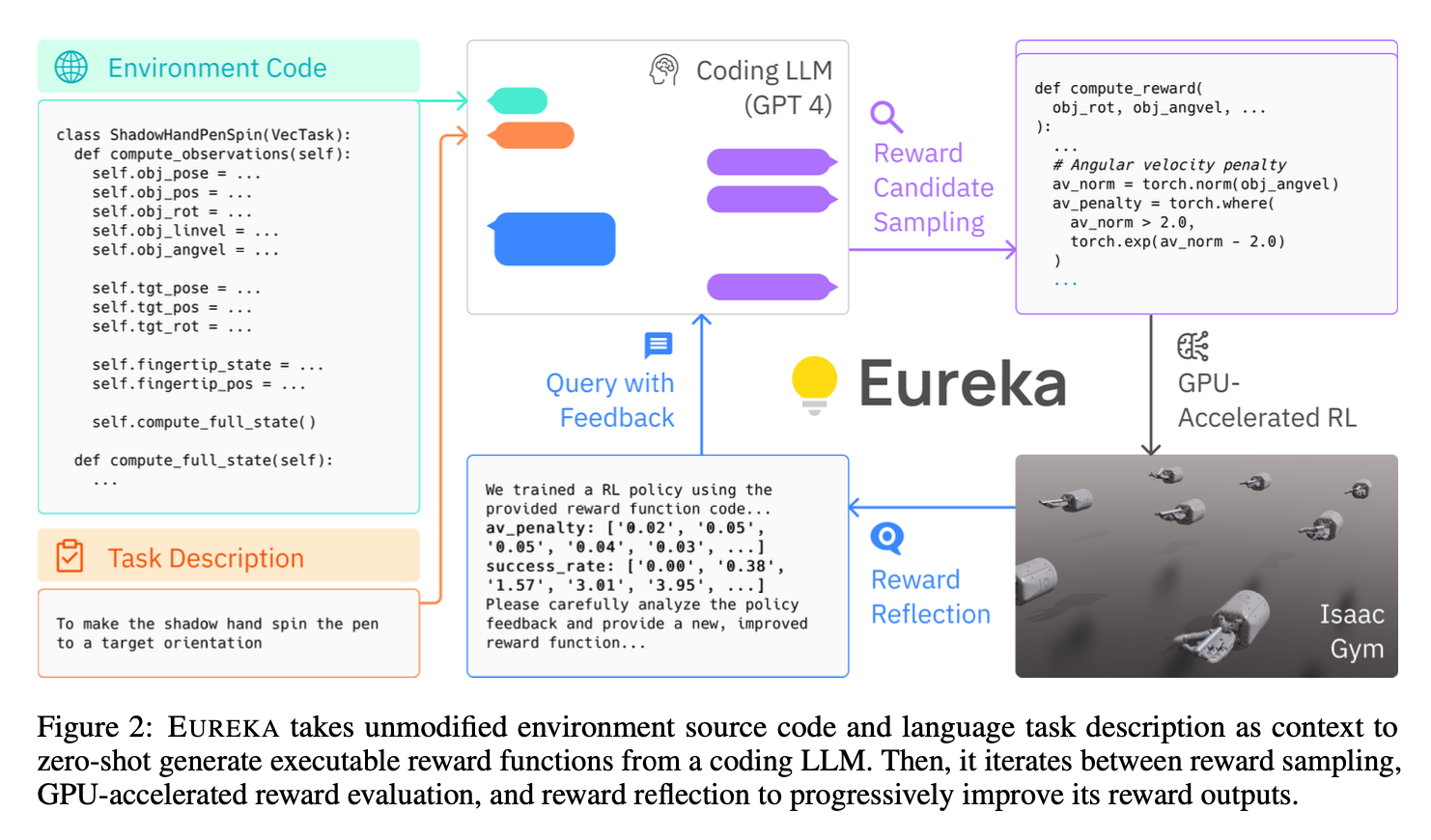
[TOC] Title: Eureka Human Level Reward Design via Coding Large Language Models 2023 Author: Yecheng Jason Ma et. al. Publish Year: 19 Oct 2023 Review Date: Fri, Oct 27, 2023 url: https://arxiv.org/pdf/2310.12931.pdf Summary of paper Motivation harnessing LLMs to learn complex low-level manipulation tasks, remains an open problem. we bridge this fundamental gap by using LLMs to produce rewards that can be used to acquire conplex skill via reinforcement learning. Contribution Eureka generate reward functions that outperform expert human-engineered rewards. the generality of Eureka also enables a new gradient-free in-context learning approach to reinforcement learning from human feedback (RLHF) Some key terms given detailed environmental code and natural language description about the task, the LLMs can generate reward function candidate sampling. As many real-world RL tasks admit sparse rewards that are difficult for learning, reward shaping that provides incremental learning signals is necessary in practice reward design problem ...