Tianjun_zhang the Wisdom of Hindsight Makes Language Models Better Instruction Followers 2023
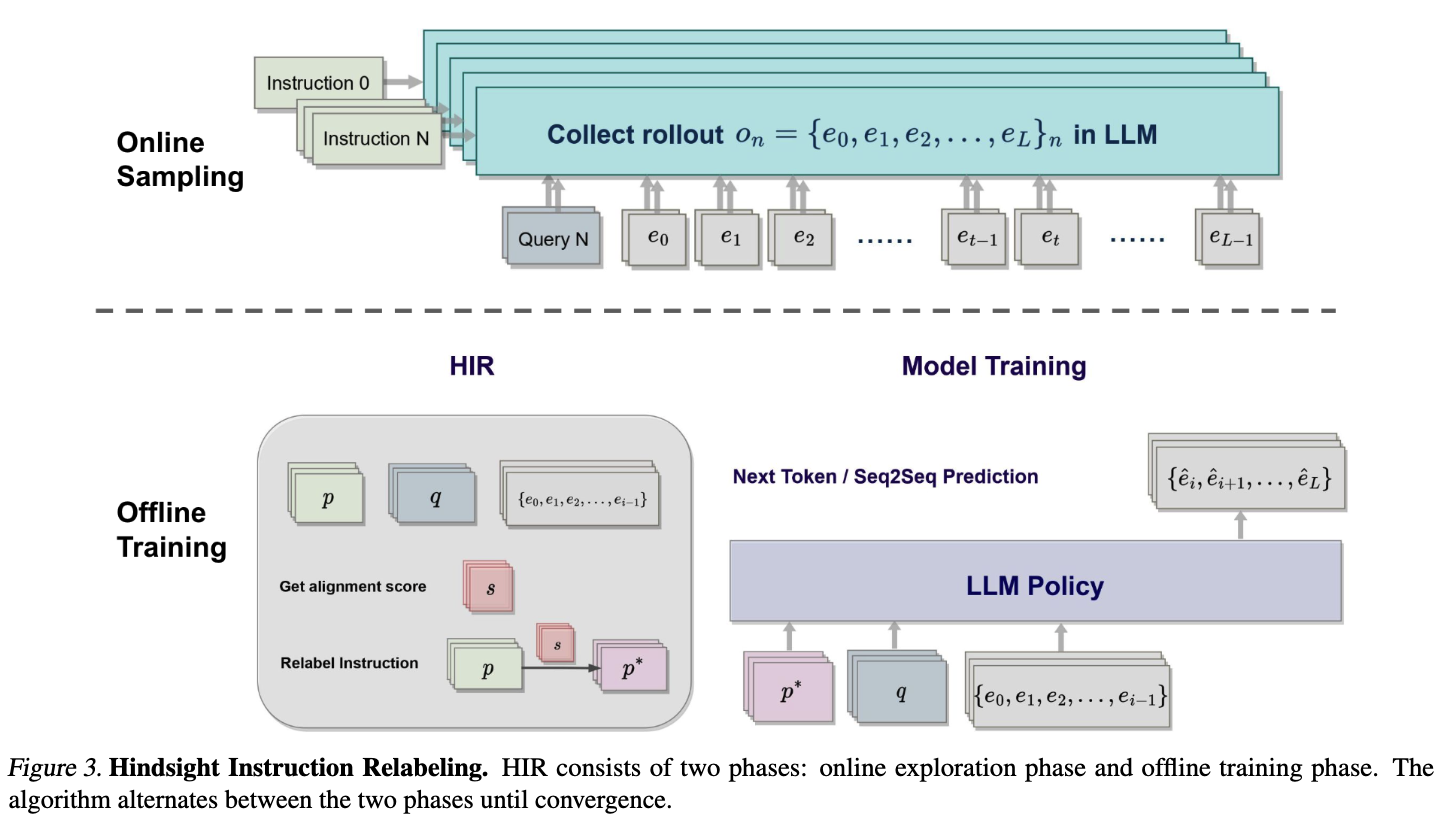
[TOC] Title: The Wisdom of Hindsight Makes Language Models Better Instruction Followers Author: Tianjun Zhang et. al. Publish Year: 10 Feb 2023 Review Date: Thu, Mar 2, 2023 url: https://arxiv.org/pdf/2302.05206.pdf Summary of paper Motivation Reinforcement learning with Human Feedback (RLHF) demonstrates impressive performance on the GPT series models. However, the pipeline for reward and value networks Contribution in this paper, we consider an alternative approach: converting feedback to instruction by relabeling the original one and training the model for better alignment in a supervised manner. Such an algorithm doesn’t require any additional parameters except for the original language model and maximally reuses the pretraining pipeline. To achieve this, we formulate instruction alignment problem in decision making. We propose Hindsight Instruction Relabeling (HIR), a novel algorithm for alignment language models with instructions. The resulting two-stage algorithm shed light to a family of reward-free approaches that utilise the hindsightly relabeled instructions based on feedback. Some key terms fine-tuning language model ...