Yuetian_weng an Efficient Spatio Temporal Pyramid Transformer for Action Detection 2022
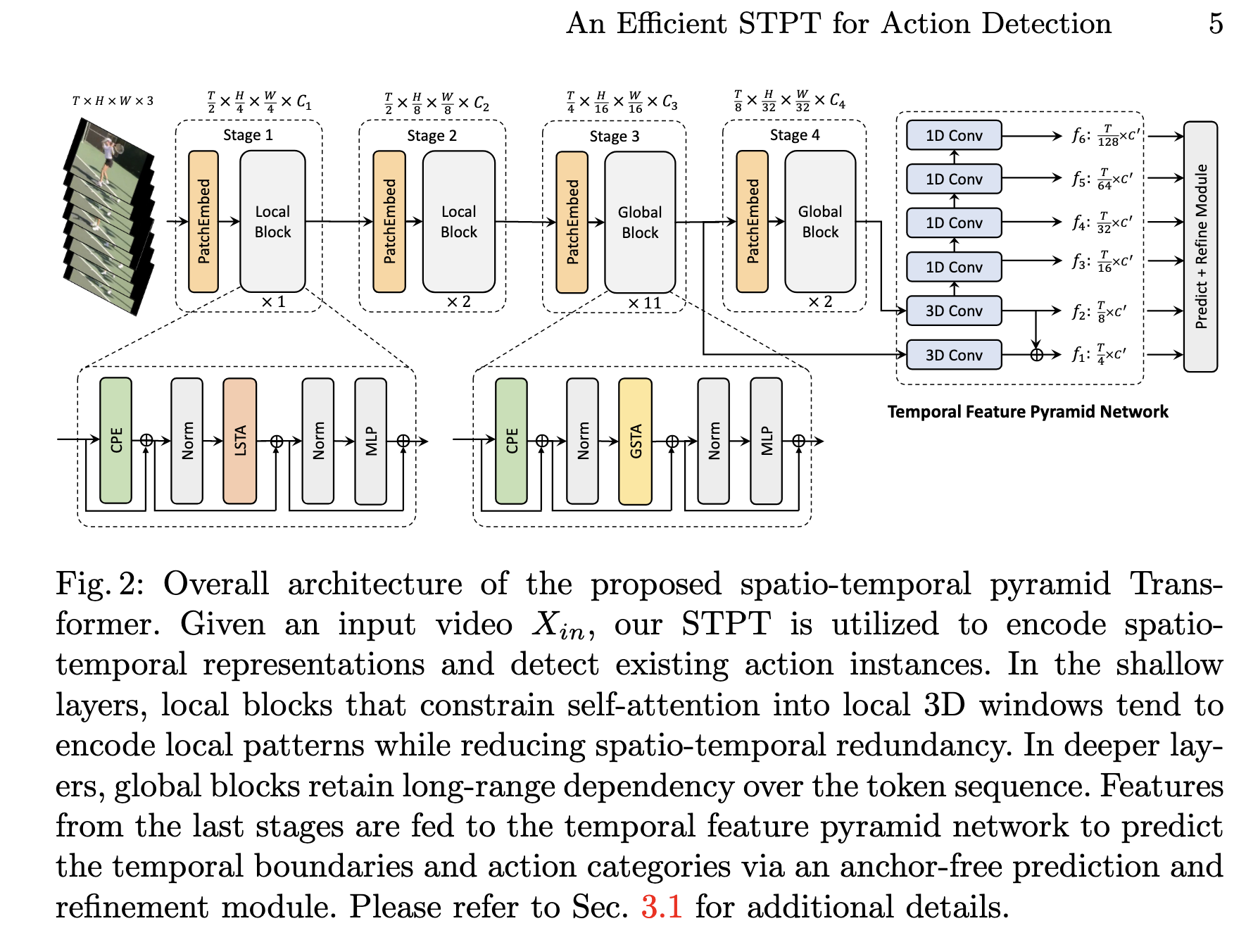
[TOC] Title: An Efficient Spatio-Temporal Pyramid Transformer for Action Detection Author: Yuetian Weng et. al. Publish Year: Jul 2022 Review Date: Thu, Oct 20, 2022 Summary of paper Motivation the task of action detection aims at deducing both the action category and localisation of the start and end moment for each action instance in a long, untrimmed video. it is non-trivial to design an efficient architecture for action detection due to the prohibitively expensive self-attentions over a long sequence of video clips To this end, they present an efficient hierarchical spatial temporal transformer for action detection Building upon the fact that the early self-attention layer in Transformer still focus on local patterns. Background to date, the majority of action detection methods are driven by 3D convolutional neural networks (CNNs), e.g., C3D, I3D, to encode video segment features from video RGB frames and optical flows however, the limited receptive field hinders the CNN-based models to capture long-term spatio-temporal dependencies. alternatively, vision transformers have shown the advantage of capturing global dependencies via the self-attention mechanism. Hierarchical ViTs divide Transformer blocks into several stages and progressively reduce the spatial size of feature maps when the network goes deeper. but having self-attention over a sequence of images is expensive also they found out that the global attention in the early layers actually only encodes local visual pattens (i.e., it only attends to its nearby tokens in adjacent frames while rarely interacting with tokens in distance frames) Efficient Spatio-temporal Pyramid Transformer ...