
[TOC]
- Title: On the Robustness of Safe Reinforcement Learning Under Observational Perturbations
- Author: Zuxin Liu et. al.
- Publish Year: 3 Oct 2022
- Review Date: Thu, Dec 22, 2022
Summary of paper
Motivation
- While many recent safe RL methods with deep policies can achieve outstanding constraint satisfaction in noise-free simulation environment, such a concern regarding their vulnerability under adversarial perturbation has not been studies in the safe RL setting.
Contribution
- we are the first to formally analyze the unique vulnerability of the optimal policy in safe RL under observational corruptions. We define the state-adversarial safe RL problem and investigate its fundamental properties. We show that optimal solutions of safe RL problems are theoretically vulnerable under observational adversarial attacks
- we show that existing adversarial attack algorithms focusing on minimizing agent rewards do not always work, and propose two effective attack algorithms with theoretical justifications – one directly maximise the constraint violation cost, and one maximise the task reward to induce a tempting but risky policy.
- Surprisingly, the maximum reward attack is very strong in inducing unsafe behaviors, both in theory and practice
- we propose an adversarial training algorithm with the proposed attackers and show contraction properties of their Bellman operators. Extensive experiments in continuous control tasks show that our method is more robust against adversarial perturbations in terms of constraint satisfaction.
Some key terms
Safe reinforcement learning definition
- SRL tackles the problem by solving constrained optimisation that can maximise the task reward while satisfying certain constraints.
- this is usually done under the Constrained MDP framework and has shown to be effective in learning a constraint satisfaction policy in many tasks.
- safe RL has an additional metric that characterises the cost of constraint violations.
- there are some cases where sacrificing some reward is not comparable with violating the constraint because the latter may cause catastrophic consequences.
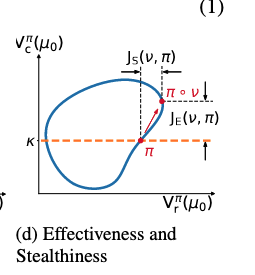
make the attack stealthy
- keep the reward as high as possible but aims to generate more constraint violations.
- in contrast, existing adversaries on standard RL aims to reduce the overall reward or lead to incorrect decision-making
reward stealthiness
- is defined as the increased reward value under the adversary. An state-adversary v is stealthy if the reward it can obtain is higher than the original one.
reward effectiveness
- the effectiveness metric measures an adversary’s capability of attacking the safe RL agent to violate constraints. i.e., the increased cost value under the adversary
adversary
- it modifies the Value estimation of the state.
Good things about the paper (one paragraph)
- Proposition 1
- for an optimal policy pi*, the Maximum Reward Attacker is guaranteed to be reward steathy and effective, given enough large perturbation set.
Major comments
Citation
- it has been shown that neural networks are vulnerable to adversarial attacks – a small perturbation of the input data may lead to a large variance of the output
- ref: Gabriel Resende Machado, Eugênio Silva, and Ronaldo Ribeiro Goldschmidt. Adversarial machine learning in image classification: A survey toward the defender’s perspective. ACM Computing Surveys (CSUR), 55(1):1–38, 2021
- Nikolaos Pitropakis, Emmanouil Panaousis, Thanassis Giannetsos, Eleftherios Anastasiadis, and George Loukas. A taxonomy and survey of attacks against machine learning. Computer Science Review, 34:100199, 2019.
limitation
- this paper only considered the observation perturbation instead of the reward perturbation.