
[TOC]
- Title: Improving Machine Translation Use Quality Estimation as a Reward Model 2024
- Author: Zhiwei He et. al.
- Publish Year: 23 Jan 2024
- Review Date: Sun, Jan 28, 2024
- url: arXiv:2401.12873v1
Summary of paper
Contribution
In this research, the authors explore using Quality Estimation (QE) models as a basis for reward systems in translation quality improvement through human feedback. They note that while QE has shown promise aligning with human evaluations, there’s a risk of overoptimization where translations receive high rewards despite declining quality. The study addresses this by introducing heuristic rules to identify and penalize incorrect translations, resulting in improved training outcomes. Experimental results demonstrate consistent enhancements across various setups, validated by human preference studies. Additionally, the approach proves highly data-efficient, outperforming systems relying on larger parallel corpora with only a small amount of monolingual data.
Some key terms
Preliminary experiment result
Overoptimisation
The researchers identified an overoptimization problem in their translation quality improvement system, where increasing rewards led to declining translation performance. This issue, observed in preliminary experiments, was termed “overoptimization” and attributed to the imperfect alignment between the reward model and human preferences, reminiscent of Goodhart’s Law.
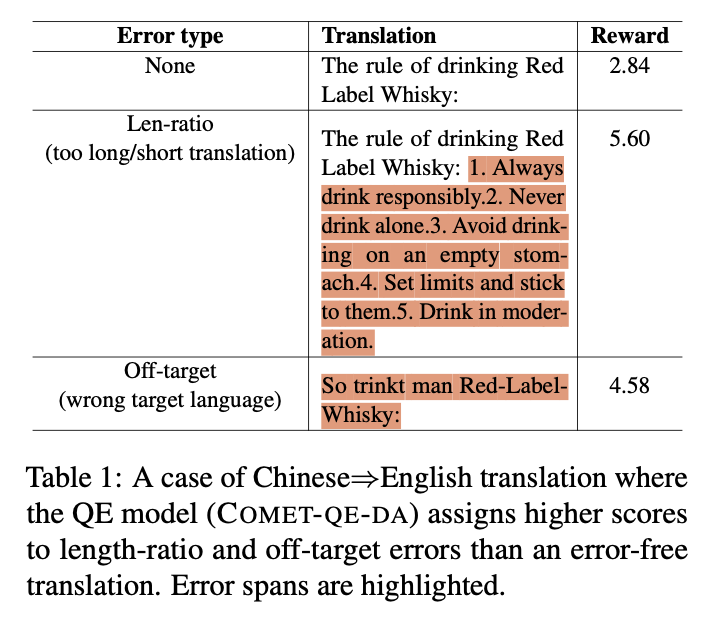
They found that the reward model sometimes gave high scores to erroneous translations, particularly those involving common machine translation errors like length-ratio discrepancies, off-target errors, and hallucinations. These errors, if rewarded highly, could propagate and disrupt the training process significantly.
To address overoptimization, the researchers proposed monitoring length-ratio and off-target errors during training and penalizing them with negative rewards. They introduced a criterion C(x, y) to identify unacceptable length ratios and off-target translations, assigning punitive rewards accordingly. This solution aimed to mitigate overoptimization and improve translation quality during training.
Summary
Very simple and straightforward solution