[TOC]
- Title: See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge Based Visual Reasoning
- Author: Zhenfang Chen et. al.
- Publish Year: 12 Jan 2023
- Review Date: Mon, Feb 6, 2023
- url: https://arxiv.org/pdf/2301.05226.pdf
Summary of paper

Motivation
- Solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect external world knowledge, and perform step-by-step reasoning to answer the questions correctly.
Contribution
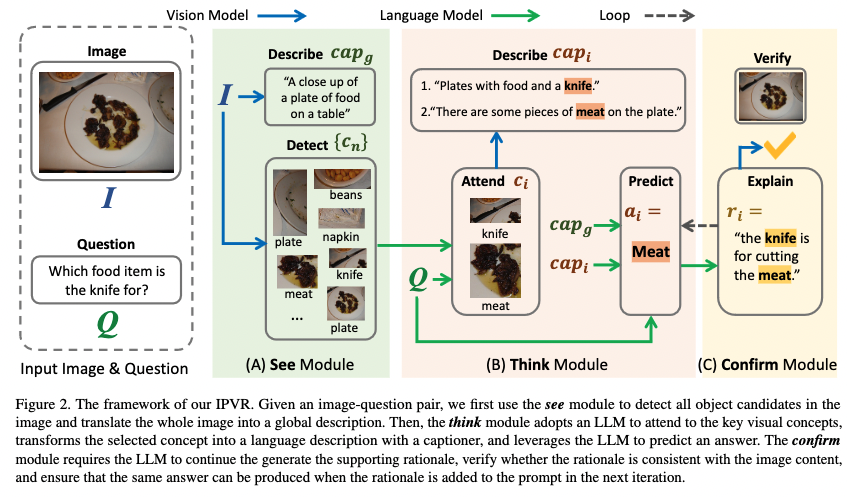
- We propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge based visual reasoning.
- IPVR contains three stages, see, think, and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer.
- The confirm stage further uses the LLM to generate the supporting rational to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently.
Some key terms
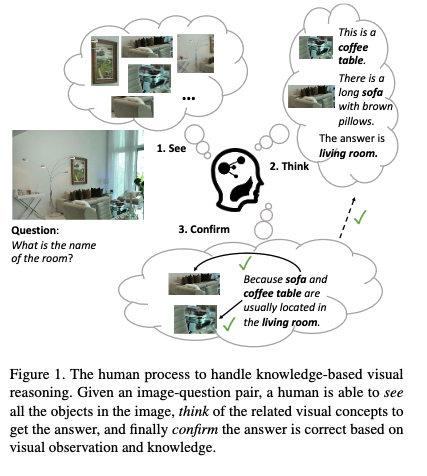
human process to handle knowledge-based visual reasoning
Dominant approaches for visual and language reasoning are mainly divided into two categories
- the first category adds additional visual perception modules to transform the visual inputs into latent inputs for LLMs, and finetunes the models with massive vision-language data.
- but it requires a large vision-language dataset to finetune the LLM and the new visual modules for each downstream task, which are typically computational intensive and time consuming
- the second category uses prompt-based methods for visual reasoning.
- first translate images into captions, which can then be used as textual prompt inputs for GPT3 models to answer the question.
- however, their model has several limitations. first the captioning process is independent of question’s semantics, limiting the caption to focus only on the image’s general aspects instead of the question-related objects
- second, their pipeline cannot provide a step-by-step reasoning trace, leaving the question-answering a black-box process.
Method


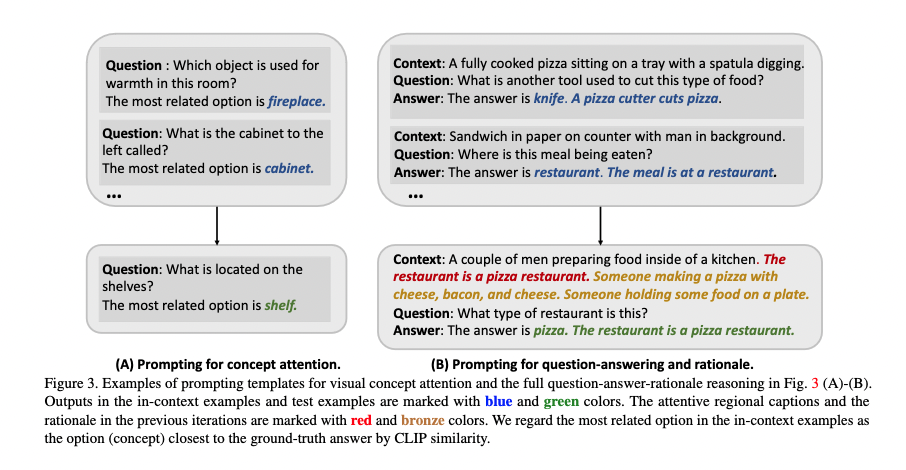
Good things about the paper (one paragraph)
-
The model gradually adds rationales in the prompt context to assist LLM to output the answer
- Assumption is that more context information is helping LLM to predict answers rather than disrupting the prediction.
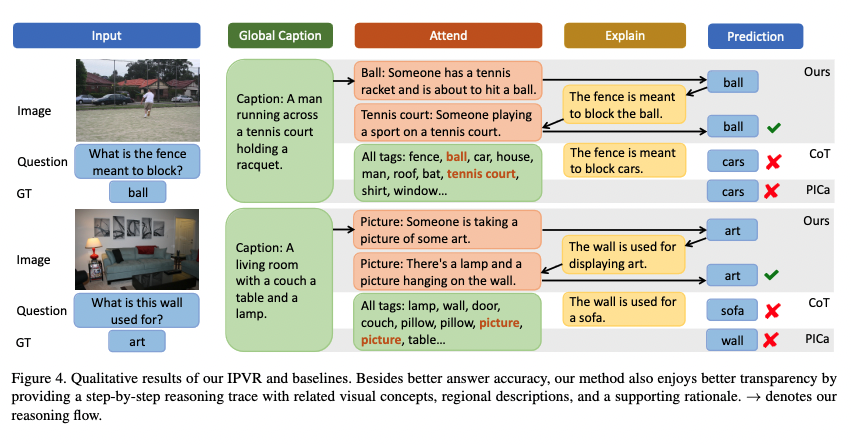
-
Compared with existing prompting methods, it not only achieves better performance but also maintains high transparency by keeping the whole trace of each reasoning step.