[TOC]
- Title: Masked World Models for Visual Control 2022
- Author: Younggyo Seo et. al.
- Publish Year: 2022
- Review Date: Fri, Jul 1, 2022
https://arxiv.org/abs/2206.14244?context=cs.AI
https://sites.google.com/view/mwm-rl
Summary of paper
Motivation

TL:DR: Masked autoencoders (MAE) has emerged as a scalable and effective self-supervised learning technique. Can MAE be also effective for visual model-based RL? Yes! with the recipe of convolutional feature masking and reward prediction to capture fine-grained and task-relevant information.
Some key terms
Decouple visual representation learning and dynamics learning
compared to DreamerV2, the new model try to decouple visual learning and dynamics learning in model based RL.
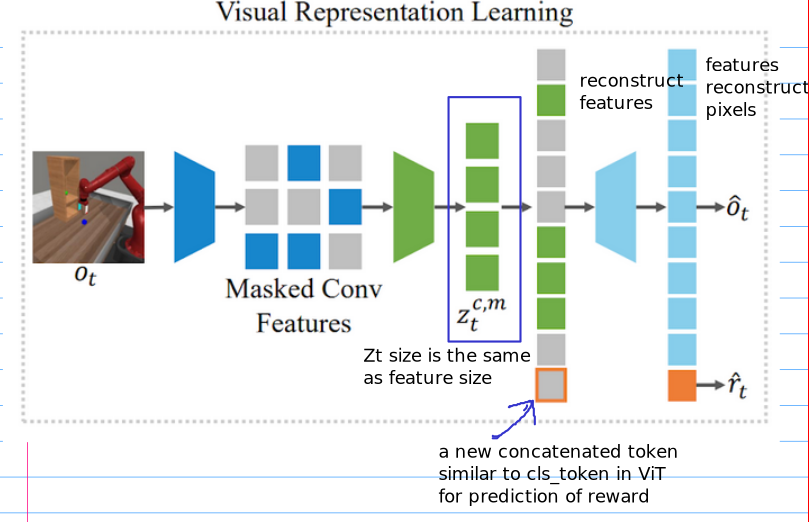
- specifically, for visual learning, we train a autoencoder with convolutional layers and vision transformer (ViT) to reconstruct pixels given masked convolutional features.
- we also introduce auxiliary reward prediction objective for the observation autoencoder
- for model based RL part, we learn a latent dynamics model that operates on the representation from the autoencoder.

Early convolutional layers and masking out convolutional features instead of pixel patches
- this approach enables the world model to capture fine-grained visual details from complex visual observations.
- we compare convolutional feature masking with pixel masking (i.e., MAE), which shows that convolutional feature masking significantly outperforms pixel masking.
- some possible reasons:
- raw pixel is noisy and less focused
- conv features is more robust
- some possible reasons:
Potential future work
We can use this model on our project
- Conv feature masking
- Dynamics learning