
[TOC]
- Title: DANLI: Deliberative Agent for Following Natural Language Instructions
- Author: Yichi Zhang
- Publish Year: 22 Oct, 2022
- Review Date: Sun, Nov 20, 2022
Summary of paper
Motivation
- reactive agent simply learn and imitate behaviours encountered in the training data
- these reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from the past experience.
Contribution
- We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark
Some key terms
Natural language instruction following with embodied AI agents
- parent class of language reward shaping AI agent.
- where an agent must interpret human language commands to perform actions in the physical world and achieve a goal.
- especially challenging is the hierarchical nature of everyday tasks, which often require reasoning about subgoals and reconciling them with the world state and overall goal.
- however, despite recent progress, past approaches are typical reactive in their execution of actions: conditioned on the rich, multimodal inputs from the environment, they perform actions directly without using an explicit representation of the world to facilitate grounded reasoning and planning.
- Such an approach is inefficient, as natural language instructions often omit trivial steps that a human may be assumed to already know
- Besides, the lack of any explicit symbolic component makes such approaches hard to interpret, especially when the agent make errors
DANLi architecture
- build a uniquely rich semantic spatial representation, acquired online from the surrounding environment and language descriptions to capture symbolic information about object instances and their physical states.
- to capture the highest level of hierarchy in tasks, we propose a neural task monitor that learns to extract symbolic information about task progress and upcoming subgoals from the dialog and action history.
- Using these elements as a planning algorithm to plan low-level actions for subgoals in the environment, taking advantage of DANLI’s transparent reasoning and planning pipeline to detect and recover from errors.

Architecture diagram
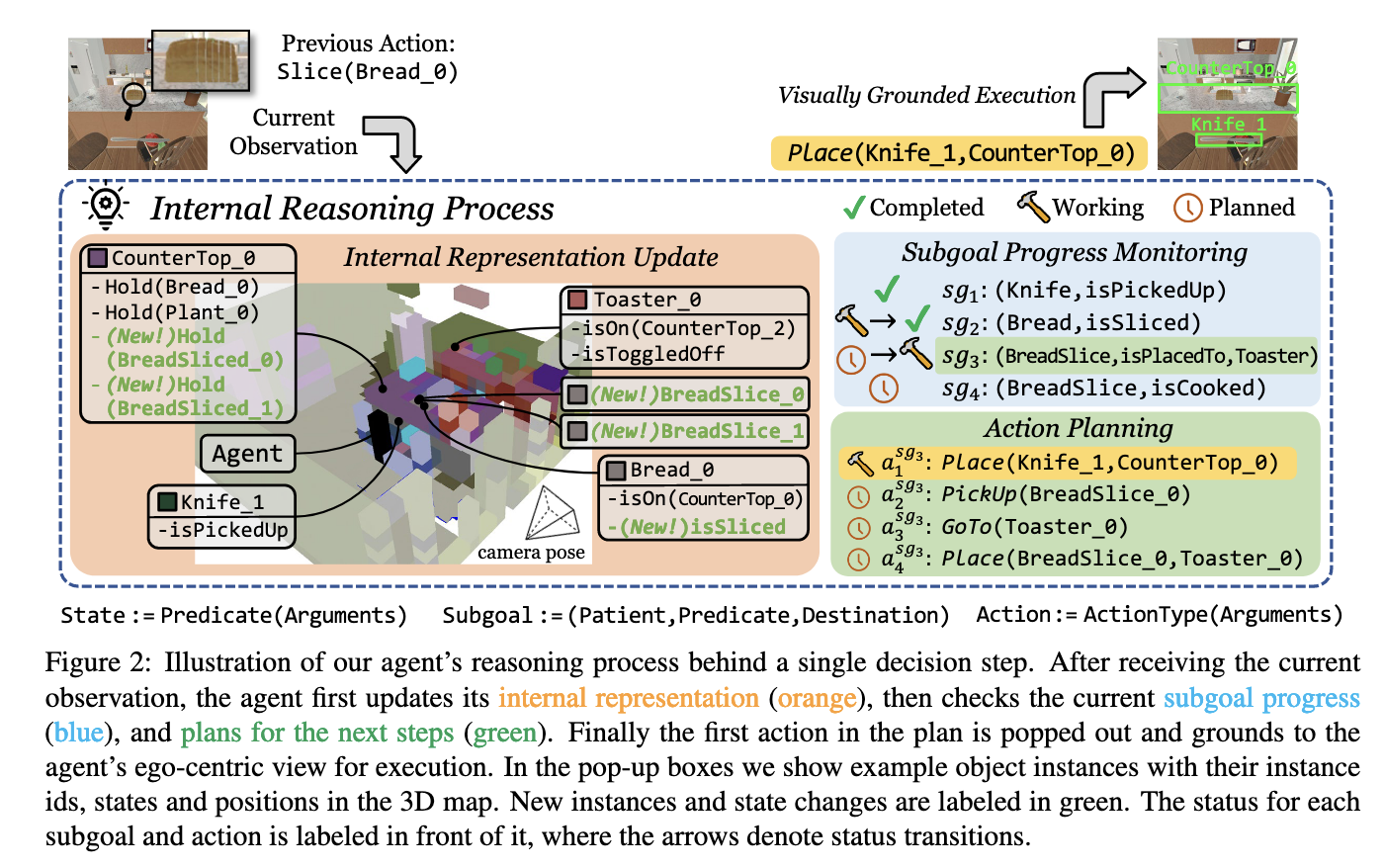
\