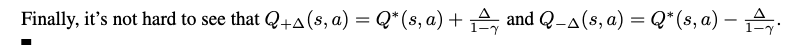[TOC]
- Title: Adaptive Reward Poisoning Attacks Against Reinforcement Learning
- Author: Xuezhou Zhang et. al.
- Publish Year: 22 Jun, 2020
- Review Date: Tue, Dec 27, 2022
Summary of paper
Motivation
- Non-adaptive attacks have been the focus of prior works. However, we show that under mild conditions, adaptive attacks can achieve the nefarious policy in steps polynomial in state-space size $|S|$
- whereas non-adaptive attacks require exponential steps.
Contribution
- we provide a lower threshold below which reward-poisoning attack is infeasible and RL is certified to be safe.
- similar to this paper, it shows that reward attack has its limit
- we provide a corresponding upper threshold above which the attack is feasible.
- we characterise conditions under which such attacks are guaranteed to fail (thus RL is safe), and vice versa
- in the case where attack is feasible, we provide upper bounds on the attack cost in the processing of achieving bad poliy
- we show that effective attacks can be found empirically using deep RL techniques.
Some key terms
feasible attack category
- non-adaptive
- the reward attack $\delta$ depends only on $(s_t, a_t, a_{s+1})$
- or adaptive where
- $\delta$ depends further on the RL agent’s learning process.
attack infeasibility
- there is a threshold such that for small reward attack, the RL agent is eventually safe.
potential based reward shaping

- we can prove that language reward shaping is a potential based reward shaping if we define $\phi$ as a function outputting the number of completed sub-goals.
- potential-based reward shaping (Ng et al., 1999) has been shown able to speed up learning which preserving the optimal policy.
Weak infeasibility certificate

Boundedness of Q-learning
- geometric series closed form