[TOC]
- Title: Reinforced Cross Modal Matching and Self Supervised Imitation Learning for Vision Language Navigation 2019
- Author: Xin Wang et. al.
- Publish Year:
- Review Date: Wed, Jan 18, 2023
Summary of paper

Motivation
Visual Language Navigation (VLN) presents some unique challenges
- first, reasoning over images and natural language instructions can be difficult.
- secondly, except for strictly following expert demonstrations, the feedback is rather coarse, since the “Success” feedback is provided only when the agent reaches a target position (sparse reward)
- A good “instruction following” trajectory may ended up just stop before you reaching the goal state and then receive zero rewards.
- existing work suffer from generalisation problem. (need to retrain the agent in new environment)
Implementation
- agent can infer which sub-instruction to focus on and where to look at. (automatic splitting long instruction)
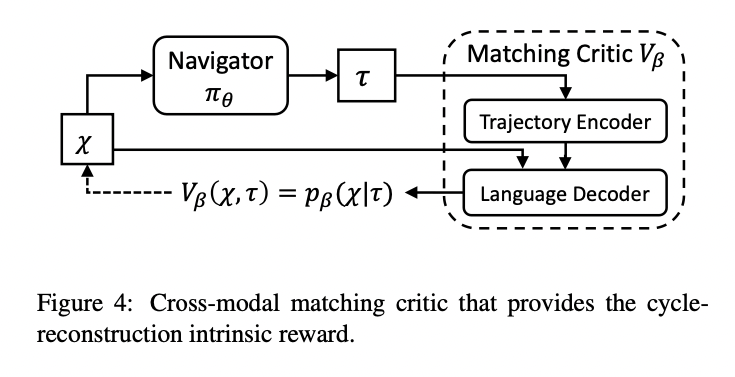
- with a matching critic that evaluates an executed path by the probability of reconstructing the original instruction from the executed path. P(original instruction | past trajectory)
- cycle reconstruction: we have P(target trajectory | the instruction) = 1, and we want to measure P(original instruction | past trajectory)
- this will enhance the interpretability as now you understand how the robot was thinking about