[TOC]
- Title: Toolformer: Language Models Can Teach Themselves to Use Tools 2023
- Author: Timo Schick et. al. META AI research
- Publish Year: 9 Feb 2023
- Review Date: Wed, Mar 1, 2023
- url: https://arxiv.org/pdf/2302.04761.pdf
Summary of paper

Motivation
- LMs exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale.
- They also struggle with basic functionality, such as arithmetic or factual lookup.
Contribution
- In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds.
- We introduce Toolformer, a model that incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system and a calendar.
Some key terms
limitation of language models
- models have several inherent limitations that can at best be partially addressed by further scaling
- these limitations include an inability to access up-to-date information on recent event (Komeili et al., 2022) and the related tendency to hallucinate facts (Maynez et al., 2020; Ji et al., 2022), difficul- ties in understanding low-resource languages (Lin et al., 2021), a lack of mathematical skills to perform precise calculations (Patel et al., 2021) and an unawareness of the progression of time (Dhingra et al., 2022).
Toolformer, which fulfills the following desiderata
- the use of tools should be learned in a self-supervised way without requiring large amounts of human annotations. This is important not only because of the costs associated with such annotations, but also because what humans find useful may be different from what a model finds useful
- the LM should not lose any of its generality and should be able to decide for itself when and how to use which tool. In contrast to existing approaches, this enables a much more comprehensive use of tools that is not tied to specific tasks.
Methods
- We let a LM annotate a huge language modelling dataset with potential API calls. We then use a self-supervised loss to determine which of these API calls actually help the model in predicting future tokens
- Finally, we finetune the LM itself on the API calls that it considers useful
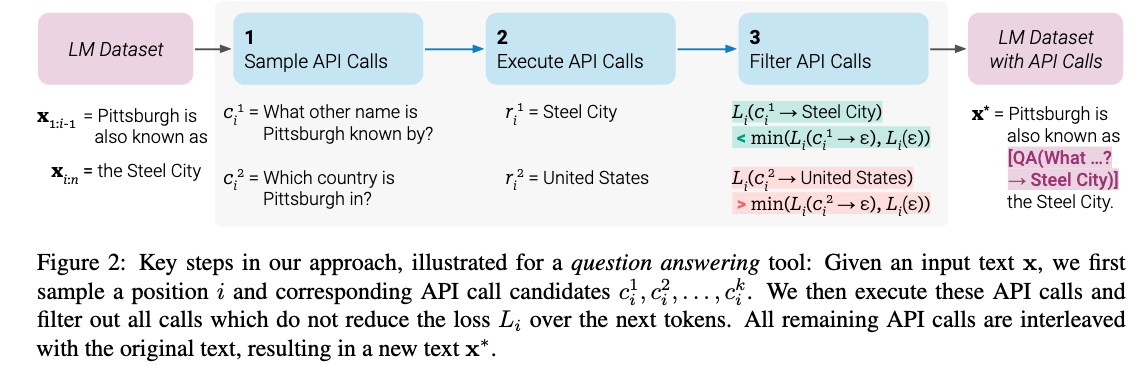
- illustrated for a question answering tool: given an input text $x$, we first sample a position $i$ and corresponding API call candidates $c_i^1, c_i^2,…,c_i^k$. We then execute these API calls can filter out all calls which do not reduce the loss $L_i$ over the next tokens
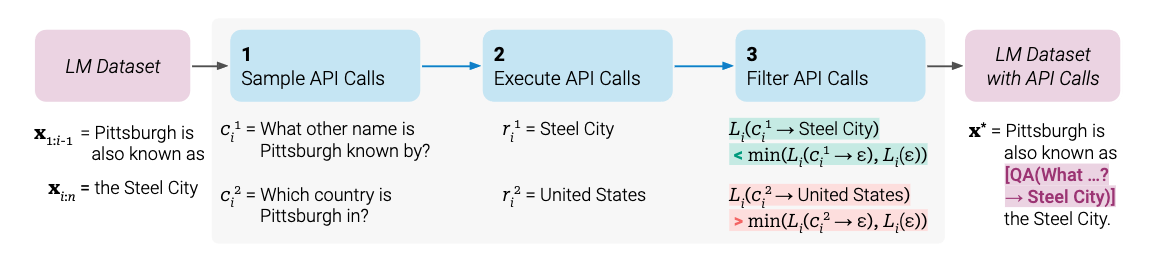

Approach details
- API call representation
- Filtering API calls

- The loss just calculates the cumulative negation of the word prediction probability log likelihood after the $i^{th}$ position
- this measures how the prefix $z$ , the API call and answer, affects the text generation.
- $L_i^-$ is the baseline loss


Highlight of this paper
- it offers a very practical way (based on in-context prompting) to utilise GPT-J, the Language model to combine with other AI systems to increase its performance in other tasks such as arithmetic tasks etc.