[TOC]
- Title: The Wisdom of Hindsight Makes Language Models Better Instruction Followers
- Author: Tianjun Zhang et. al.
- Publish Year: 10 Feb 2023
- Review Date: Thu, Mar 2, 2023
- url: https://arxiv.org/pdf/2302.05206.pdf
Summary of paper

Motivation
- Reinforcement learning with Human Feedback (RLHF) demonstrates impressive performance on the GPT series models. However, the pipeline for reward and value networks
Contribution
- in this paper, we consider an alternative approach: converting feedback to instruction by relabeling the original one and training the model for better alignment in a supervised manner.
- Such an algorithm doesn’t require any additional parameters except for the original language model and maximally reuses the pretraining pipeline.
- To achieve this, we formulate instruction alignment problem in decision making. We propose Hindsight Instruction Relabeling (HIR), a novel algorithm for alignment language models with instructions.
- The resulting two-stage algorithm shed light to a family of reward-free approaches that utilise the hindsightly relabeled instructions based on feedback.
Some key terms
fine-tuning language model
- the most widely adopted approach is to deploy reinforcement learning (RL) algorithms to optimize for a manually defined or learned “alignment score”.
- Impressive progress has been made in this direction, including the more recently released GPT series model (OpenAI, 2022)
- it is less data-efficient if it only makes use of the success instruction-output pairs, completely abandoning the ones that do not align.
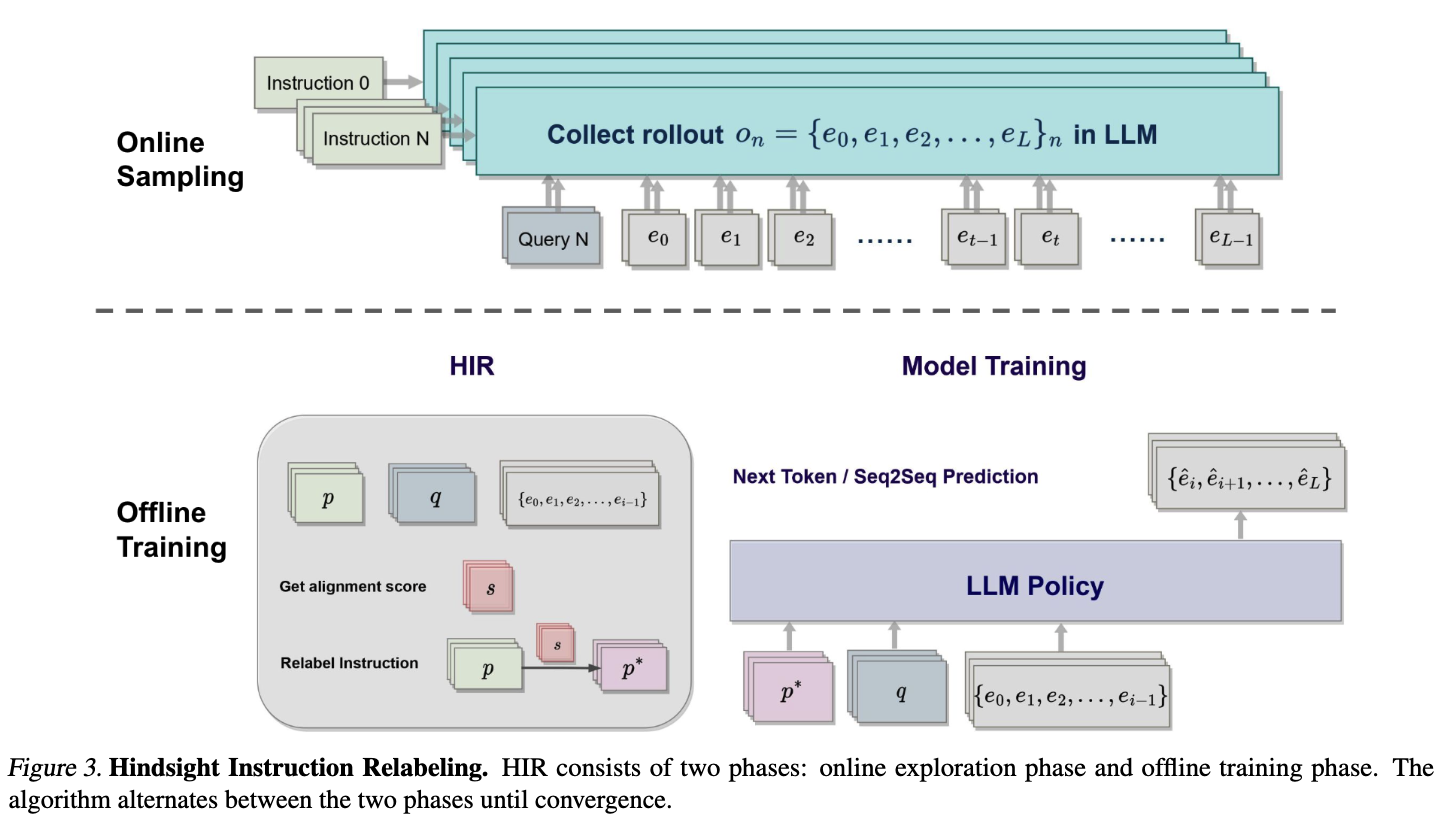
Hindsight Instruction Relabeling (HIR)
- adopts the central idea of relabeling the instructions in a hindsight fashion based on the generated outputs of the language model.
- HIR alternates between two phases
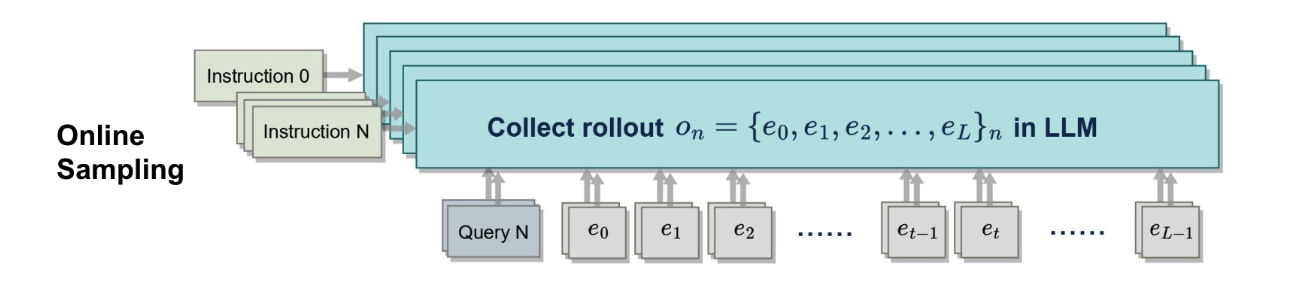
- an online sampling phrase to generate a dataset of instruction-output pairs,
- along with an offline learning phrase that relabels the instructions of each pair and performs standard supervised learning
- an online sampling phrase to generate a dataset of instruction-output pairs,
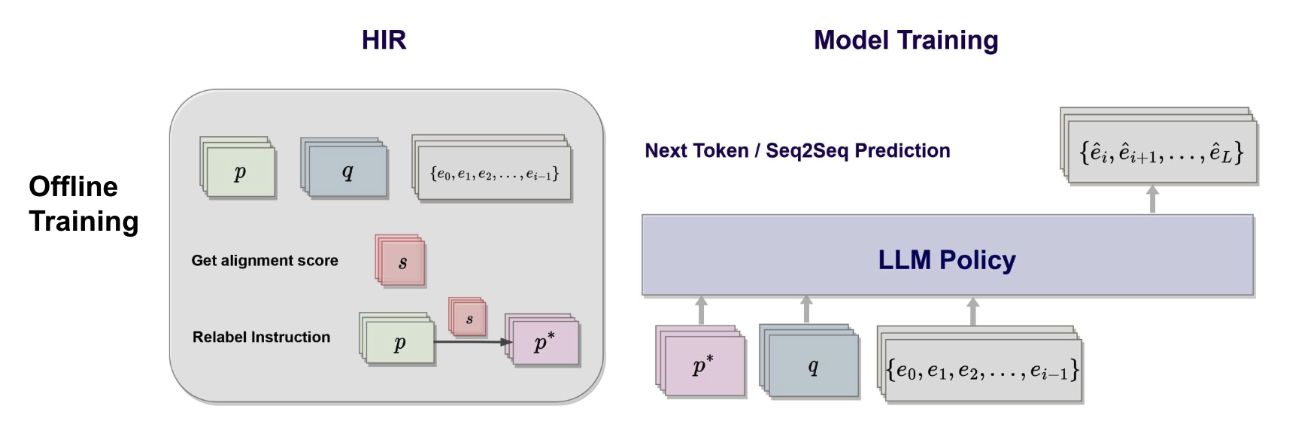
Offline Relabeling
- The key component of our algorithm is the offline relabelling part. In this part, for every instruction-output pair $(p,q,o)$ that are not necessarily aligned
- $p$ space of instructional prompt $p$
- $q$ state space of input token sequence, used as query
- $o$ is the output sequence (actions)
- we relabel this pair with a new instruction that can align with the outcome of the model $(p*, q, o)$
- The new instruction $p*$ is generated based on the feedback function $\mathcal R(p,q,o)$ and the instruction generation function $\phi(p,q,o,r)$, which can either be learned or scripted.
- EXAMPLE
- in the framework of RLHF, if the learned reward model $\mathcal R(p,q,o)$ generates a score that ranks about 75% as in the training data, we can give additional scripted instructions to the model such as “give me an answer that rank about 75% in training data”.
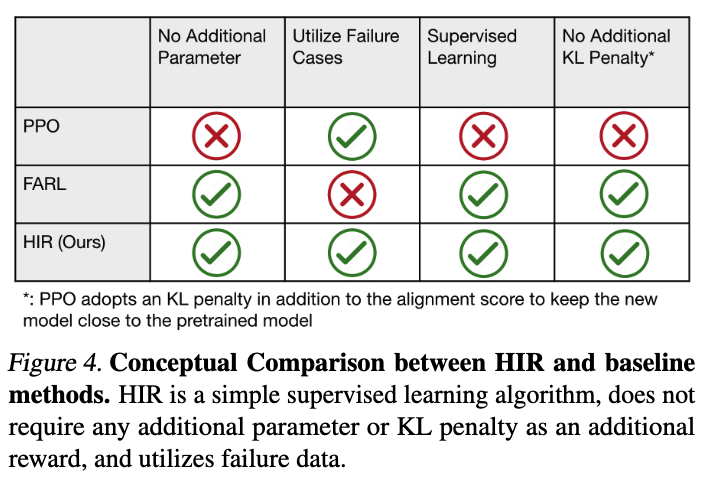
Conceptual Comparison between HIR and baseline methods