[TOC]
- Title: Reward Model Ensembles Help Mitigate Overoptimization
- Author: Thomas Coste et. al.
- Publish Year: 10 Mar 2024
- Review Date: Thu, May 9, 2024
- url: arXiv:2310.02743v2
Summary of paper

Motivation
- however, as imperfect representation of the “true” reward, these learned reward models are susceptible to over-optimization.
Contribution
- the author conducted a systematic study to evaluate the efficacy of using ensemble-based conservative optimization objectives, specially worst-case optimization (WCO) and uncertainty-weighted optimization (UWO), for mitigating reward model overoptimization
- the author additionally extend the setup to include 25% label noise to better mirror real-world conditions
- For PPO, ensemble-based conservative optimization always reduce overoptimization and outperforms single reward model optimization
Some key terms
Overoptimization
- a phenomenon in which policy optimization appears to be making progress according to the learned reward model, but in reality begins to regress with respect to the true reward function
-

Label noises
- In the real-world RLHF setup, in which agreement rates among human annotators are typically between 60% - 75% (Ziegler et al., 2019; Stiennon et al., 2020; Dubois et al., 2023).
Best of N Sampling

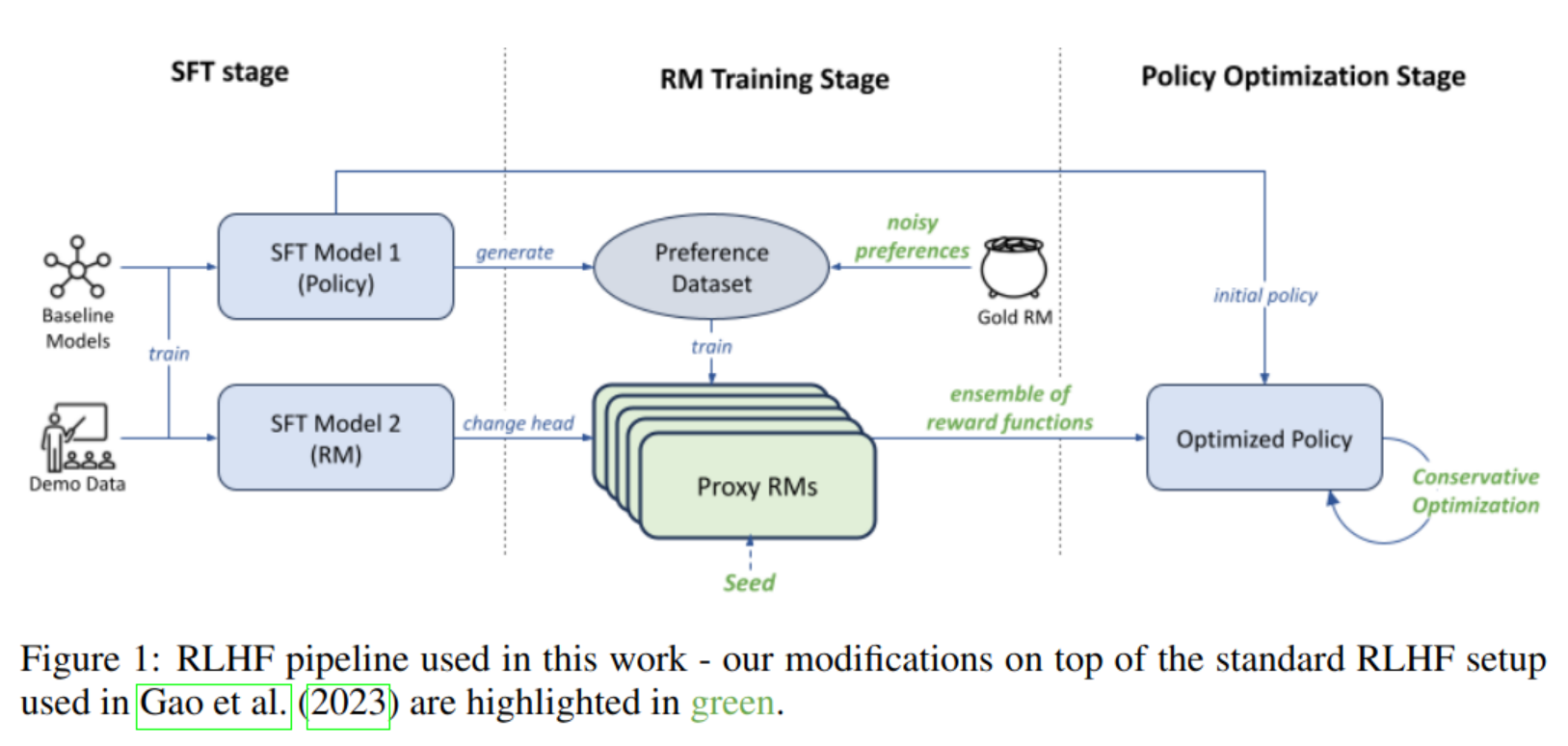
Method: reward model ensemble
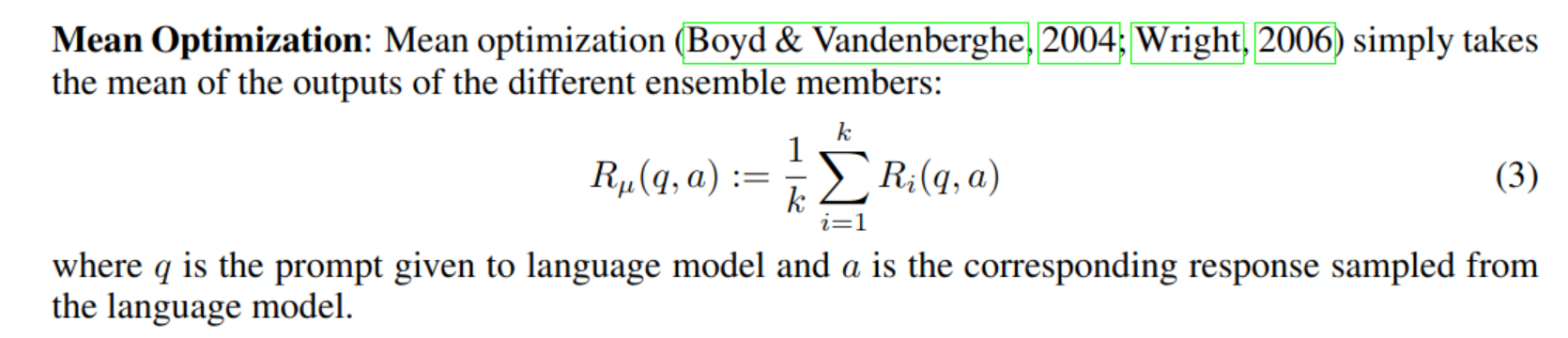


Results
for PPO, with a small KL penalty coefficient of 0.01 ($\beta$), WCO and UWO both successfully prevent overoptimization.
Summary
Use ensemble of reward models