[TOC]
- Title: Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
- Author: Thomas Carta el. al.
- Publish Year: 6 Sep 2023
- Review Date: Tue, Apr 23, 2024
- url: arXiv:2302.02662v3
Summary of paper

Summary
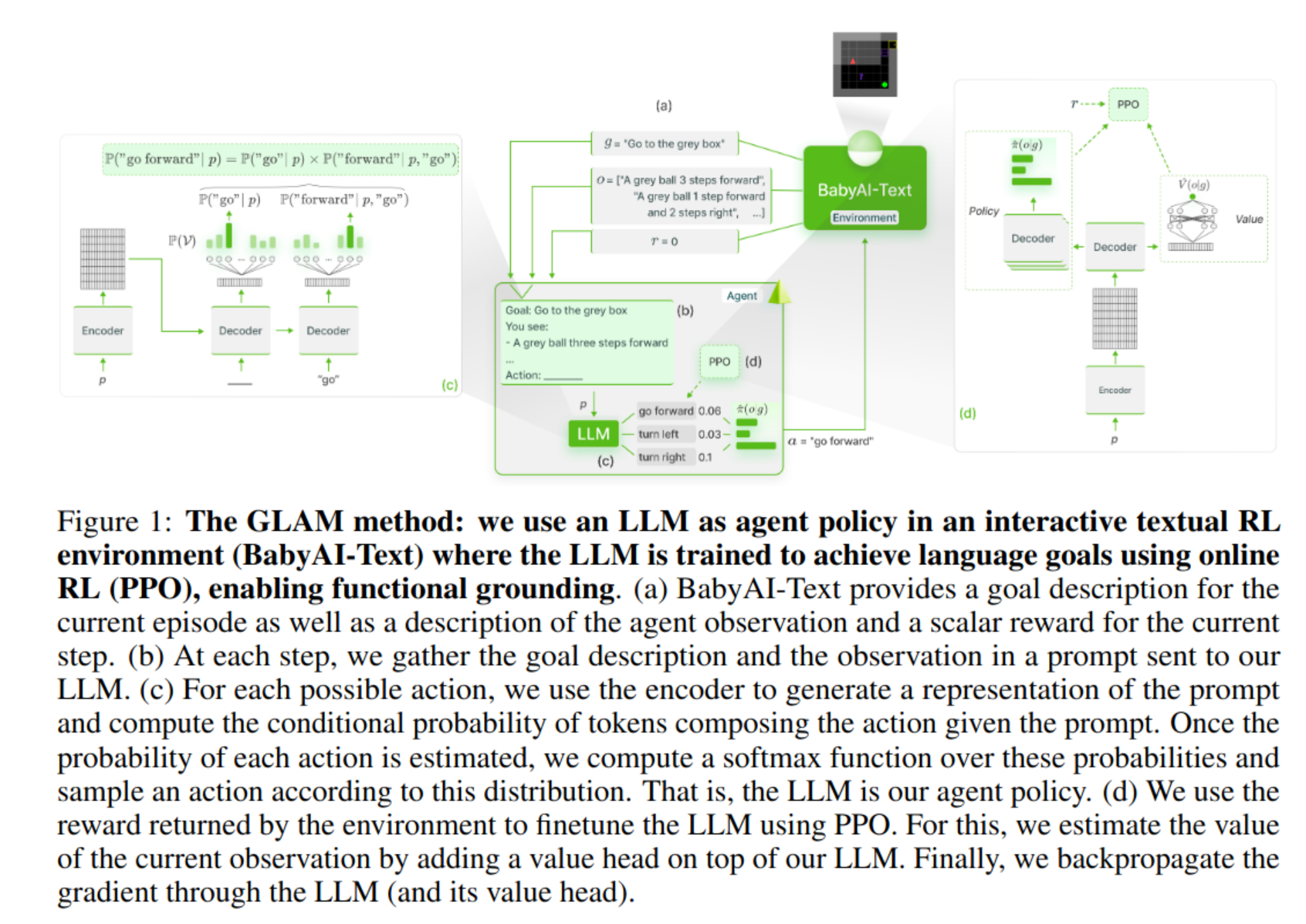
The author considered an agent using an LLM as a policy that is progressively updated as the agent interacts with the environment, leveraging online reinforcement learning to improve its performance to solve goals (under the RL paradigm environment (MDP))
The author studied several questions
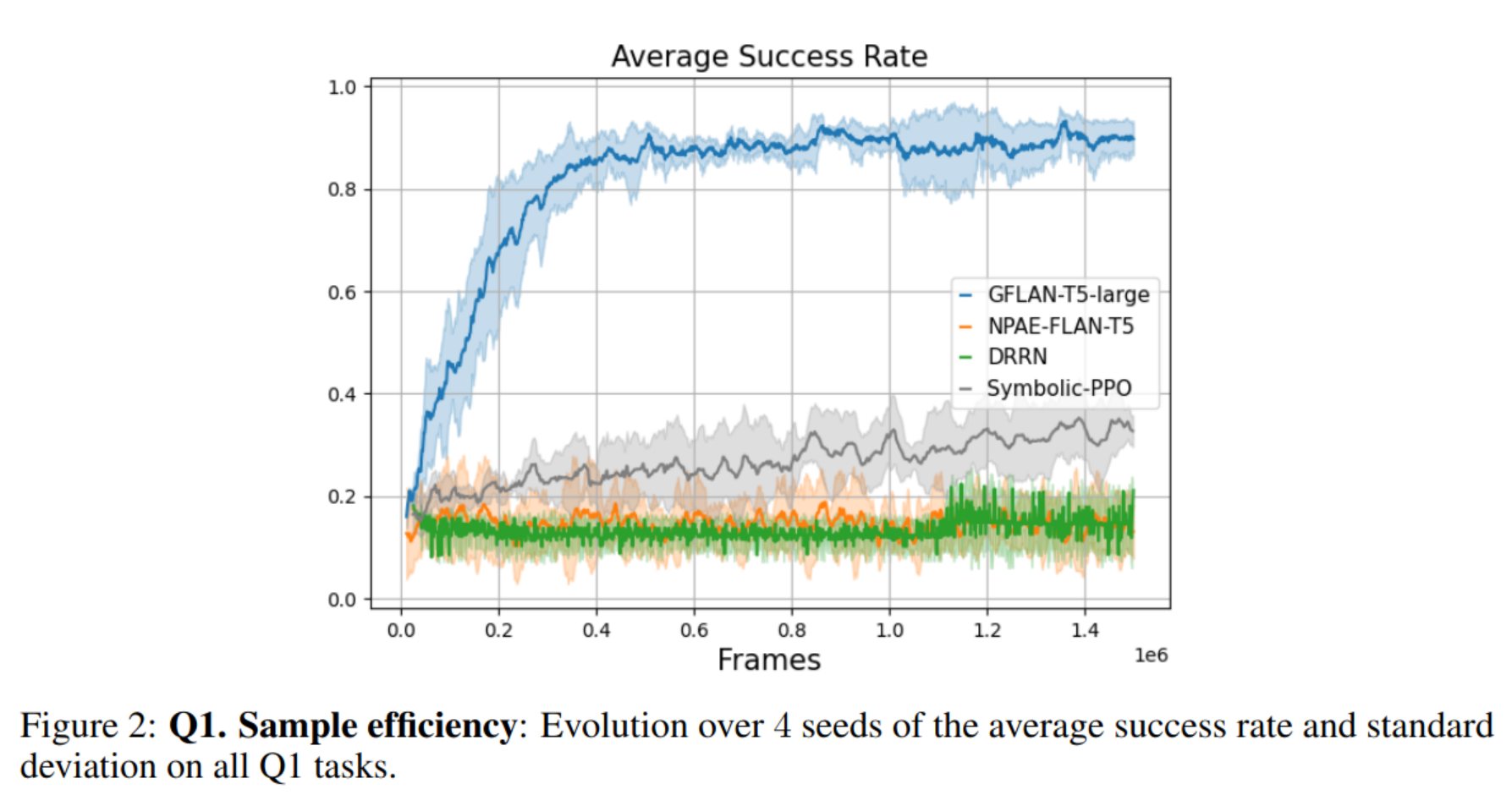
- Sample efficiency How fast can an LLM adapt and learn to solve various spatial and navigation problems specified in natural language? How does the use of pre-trained knowledge from LLM boosts sample efficiency?
- Generalization to new objects: Once functionally grounded, how can an LLM generalize to various kinds of changes about objects, yet staying in trained tasks?
- Generalization to new tasks: How can such an interactively trained LLM perform zero-shot generalization to new tasks? How does generalization depend on the kind of new tasks?
- Impact of online interventions: What is the empirical impact of grounding using online RL with incremental interactions in comparison with offline Behavioral Cloning from a dataset of expert trajectories?
env: https://minigrid.farama.org/environments/minigrid/CrossingEnv/
Sample efficiency
Generalisation
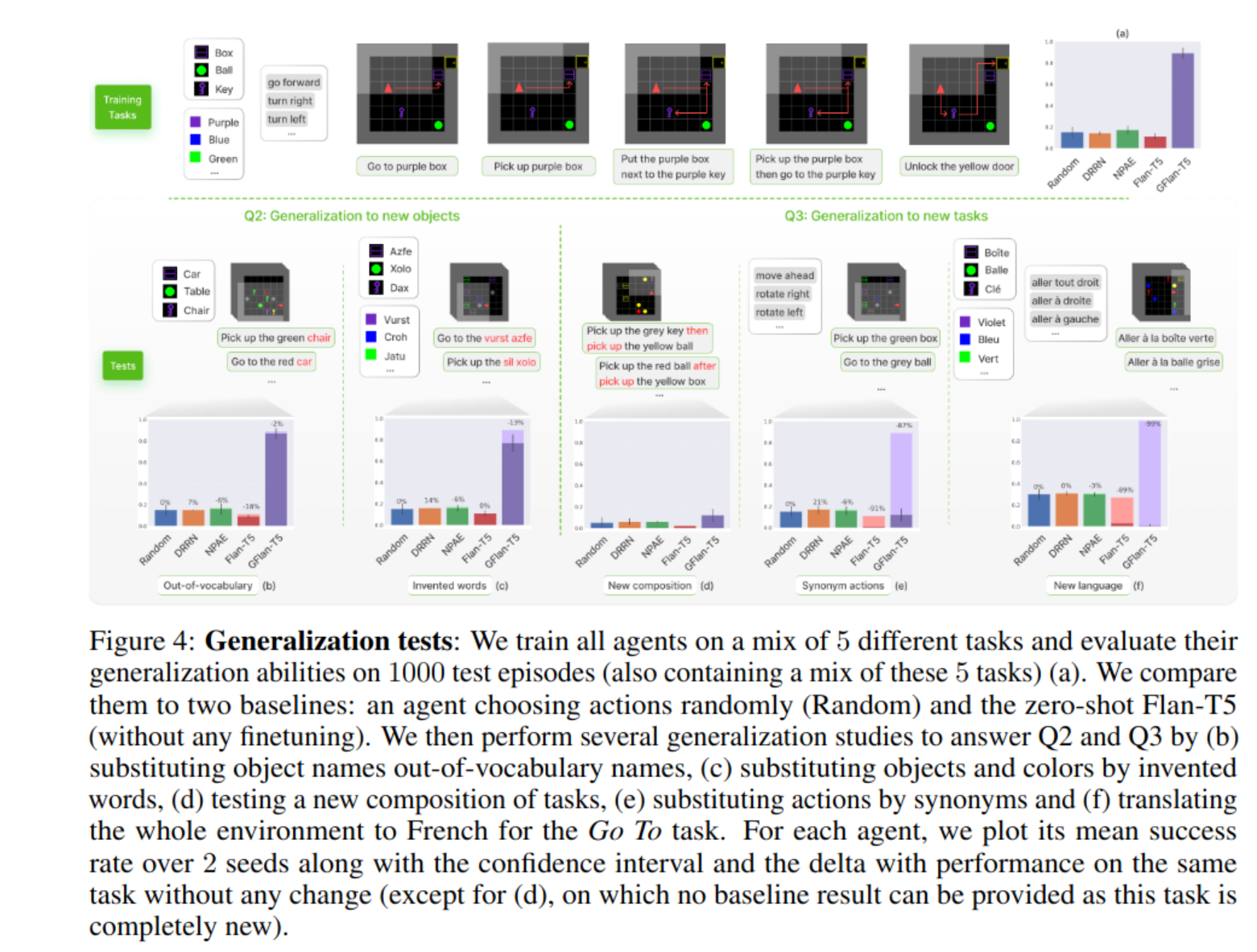
-
we see that d (testing a new composition of tasks) becomes difficult for LLM policy agent (though others also failed)
-
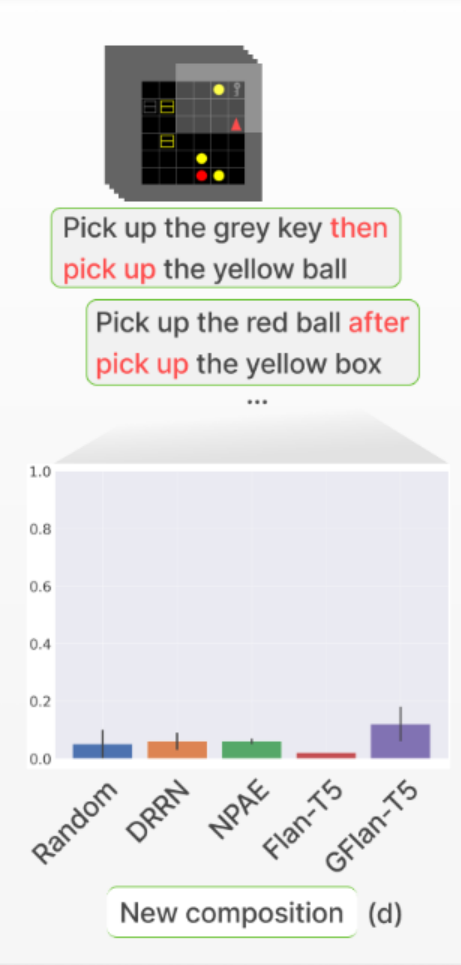

- the author claimed that it is because none of the agents managed to master the Pick up
object Athen go toobject Btask.