[TOC]
- Title: Plan Explanations as Model Reconciliation: Moving beyond explanation as soliloquy
- Author: Tathagata Chakraborti
- Publish Year: 30 May 2017
- Review Date: Tue, Sep 19, 2023
- url: https://arxiv.org/pdf/1701.08317.pdf
Summary of paper

Motivation
- Past work on plan explanations primarily involved AI system explaining the correctness of its plan and t he rationale for its decision in terms of its own model. Such soliloquy is inadequate (think about the case where GPT4 cannot find errors in PDDL domain file due to over confidence)
- in this work, the author said that due to the domain and task model difference between human and AI system, the soliloquy is inadequate.
Contribution
- They show how explanation can be seen as a “model reconciliation problem” (MRP), where AI system in effect suggests changes to the human’s model, so as to make its plan be optimal with respected to that changed human model. In other words, they need to update human’s mindset about the domain and task model such that the plan generated from the AI system fits human’s expectation.
Some key terms
Definition of a classical planning problem


explicable: i.e., generate plans that also make sense with respect to the humans’ model.
- limitation: Such explicability requirement however puts additional constraints on the agent’s plans, and may not always be feasible
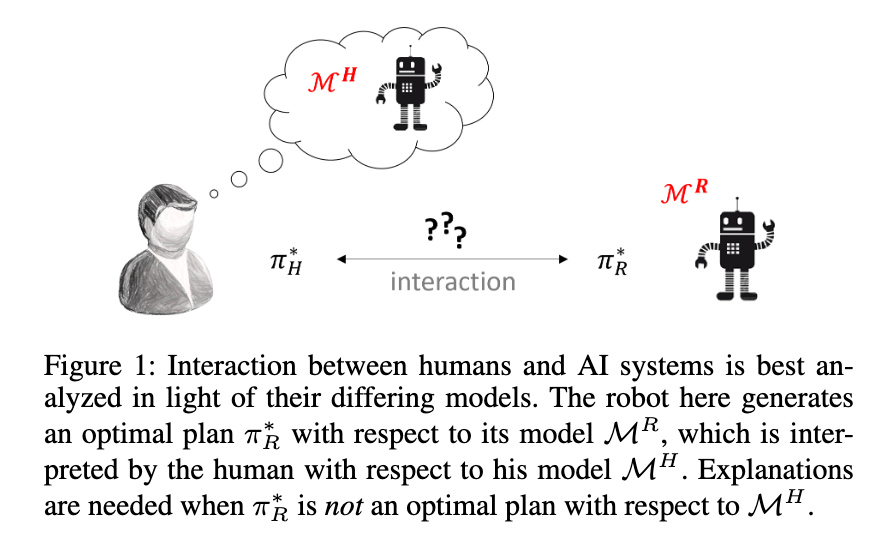
being called on to “explain” its plan: when the robot’s plan is different from what the human would expect given his model of the world, t he robot wil lbe called on to “explain” its plan
- the author posit that such explanations should be seen as the robot’s attempt to move the human’s model to be in conformance with its own.
model reconciliation problem (MRP)
- which aims to make minimal changes to the human’s model to bring it closer to the robot’s model
- comment: would this also apply to the domain fixing situation?
- this paper’s assumption: the human’s model is made available and is in PDDL format just like the robot’s one.
- here, the planner does not change its own behavior, but rather corrects the human’s incorrect perception of its model via explanations.
multi model explanations
- in the paper, the author gave an example how an AI system should explain their plan when the action definition of the robot’s PDDL model differs from ones of the human’s PDDL model
- I think there is a implicit assumption that the robot’s PDDL model is self-justifying. (i.e., no semantic errors within its own system)
formal mathematical terms
-
$\delta_{\mathcal M}(\mathcal I, \pi) \models G$: a sequential transition from initial state $\mathcal I$ to goal state $G$
-
$C(\pi^{}, M^{R}) = C^{}_{M^{R}}$ : the total cost of optimal policy $\pi^*$ under robot PDDL model $M$.
-
$c_a$ is a single cost of action $a$
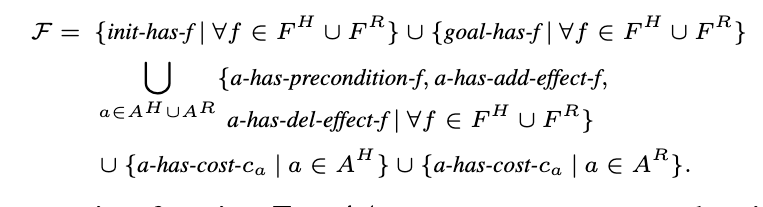
- $\mathcal F$ is the fluent universe. fluent is different from state, a state is a compound of fluents
- new action set $\Lambda$ containing unit model change actions such that there is only a single change to a domain at a time.
- $s_1 \Delta s_2$ means the number of changes from state $s_1$ to $s_2$
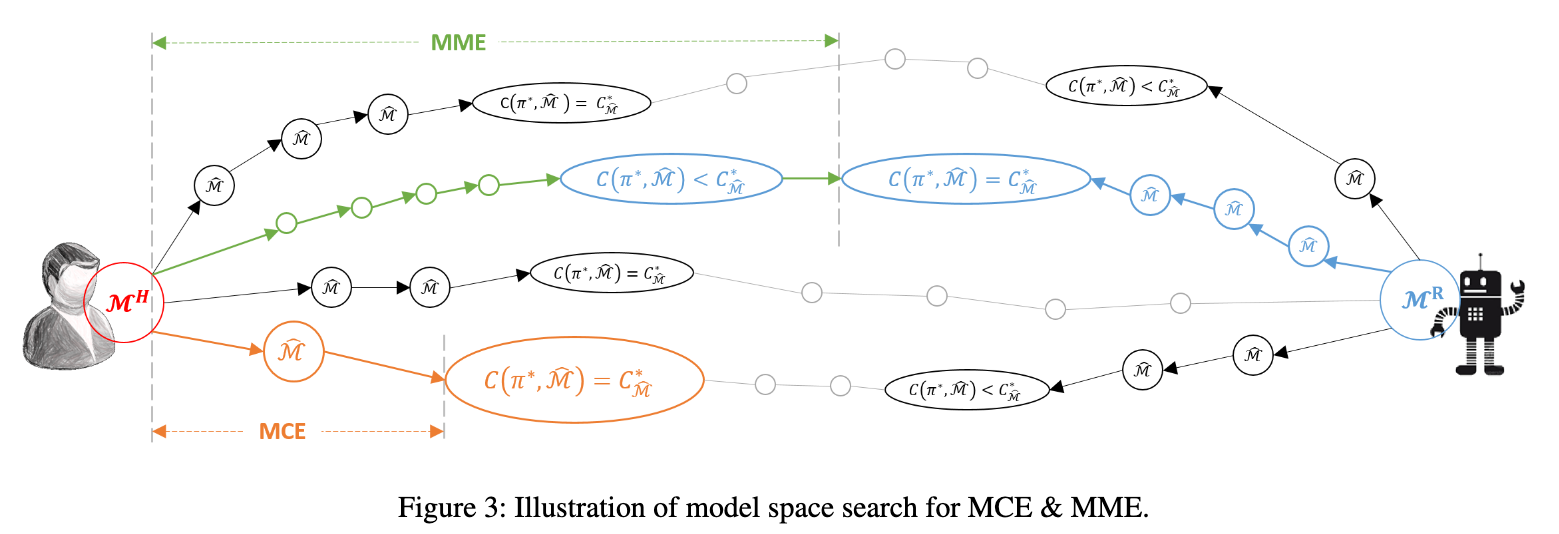
- Objective of this work: transforming model space from human model $\mathcal M^{H}$ to $\hat{\mathcal M}$

- the difference between the cost of the robot-generated optimal policy $\pi^*$ in the transformed model and the cost of the local optimal policy should be smaller than the one between the cost in Human model and the cost of its local optimal policy.

Good things about the paper (one paragraph)
- it provided a new paradigm about how to regard the explanation of PDDL models.
- The math part is however, too heavy for layman.
Potential future work
Limitation:
- this paper assumed that the expert’s domain model is available and is in PDDL format. However, usually expert’s model is encoded in natural language and there is no available ground truth in PDDL format.