[TOC]
- Title: When Attention Meets Fast Recurrence: Training Language Models with Reduce Compute
- Author: Tao Lei
- Publish Year: Sep 2021
- Review Date: Jan 2022
Summary of paper

As the author mentioned, the inspiration of SRU++ comes from two lines of research:
- paralleization / speed problem of Original RNN
- leveraging recurrence in conjunction with self-attention
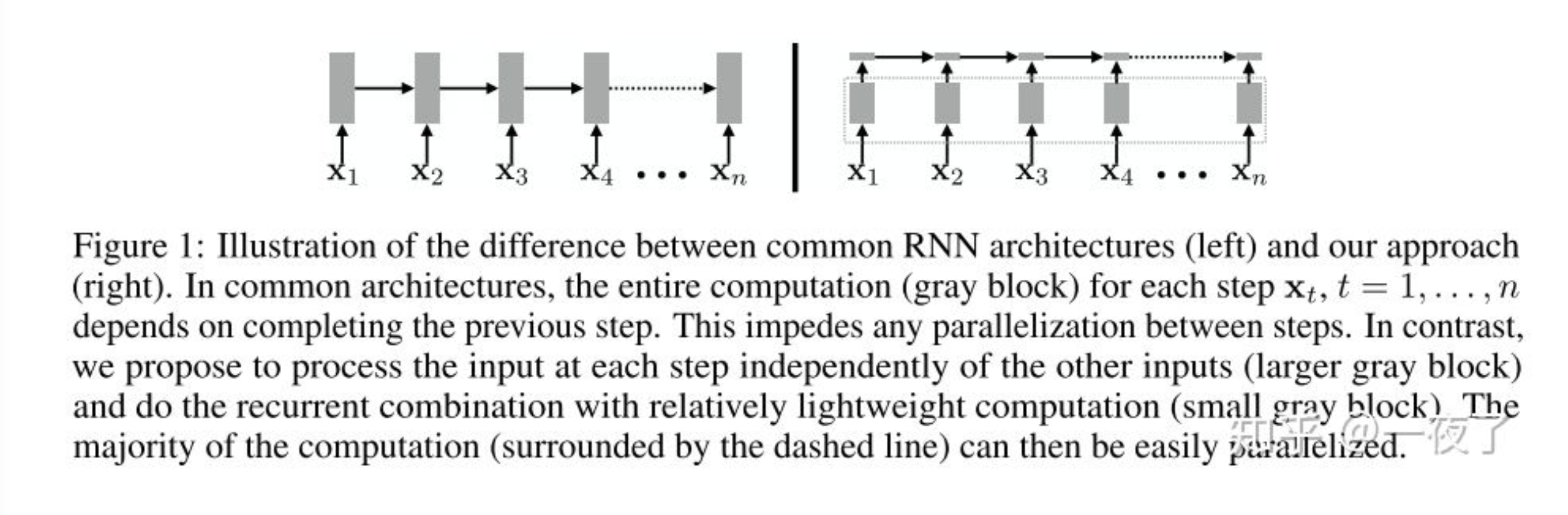
Structure of SRU++
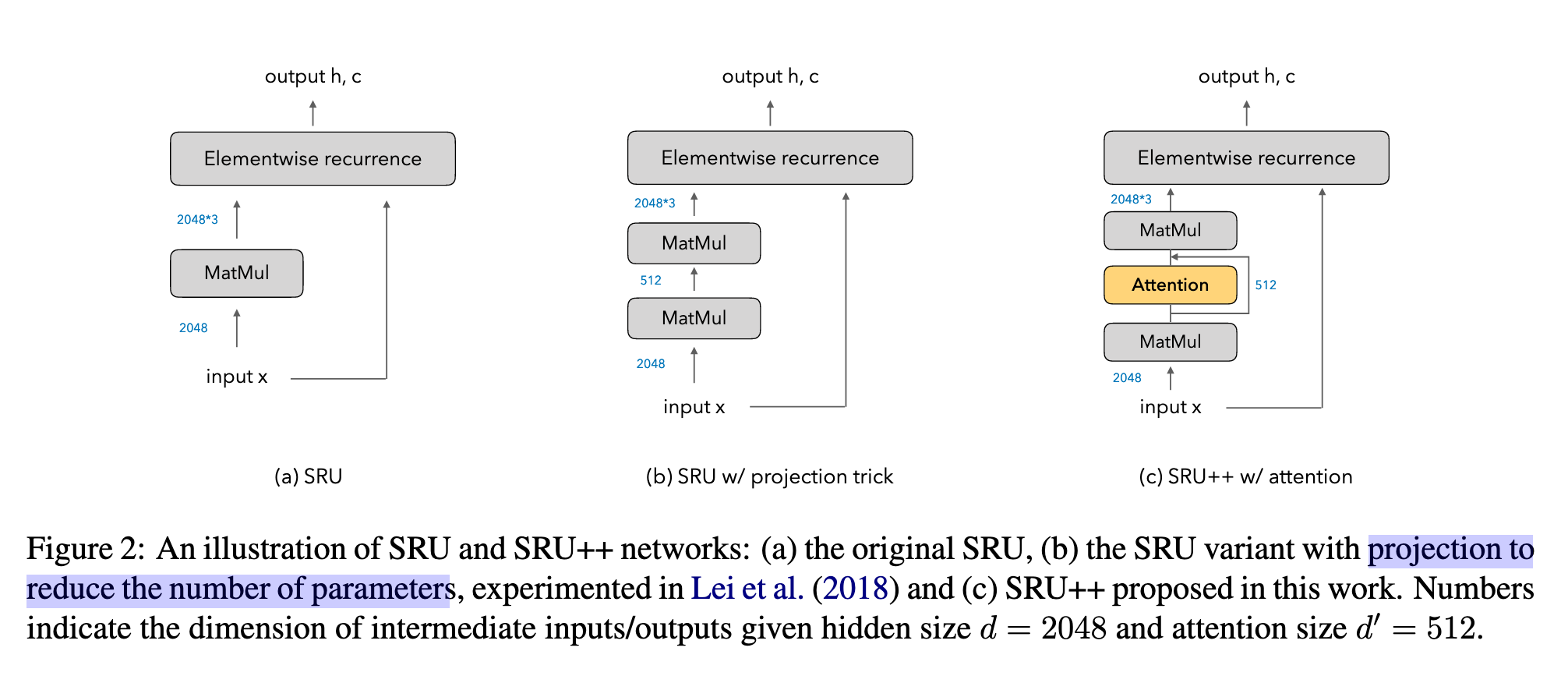
New discovery :little attention is needed given recurrence.
Similar to the observation of Merity (2019), they found using a couple of attention layers sufficient to obtain SOTA results.
Where to use attention
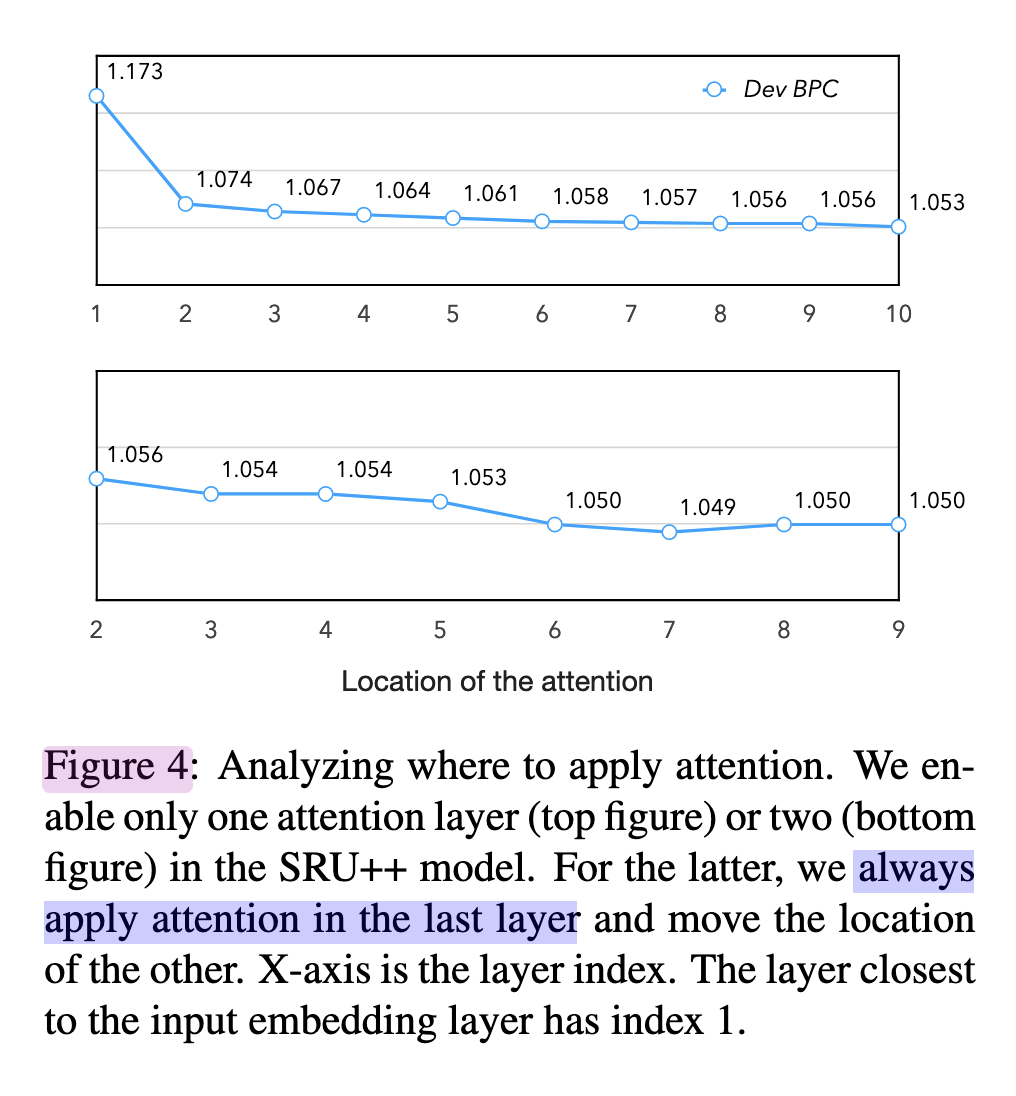
Putting the attention to higher layer closer to the output will get better result.
e.g., for a 10-layer model, use attention at 7th and 10th layer.