[TOC]
- Title: Human Level Atari 200x Faster
- Author: Steven Kapturowski et. al. DeepMind
- Publish Year: September 2022
- Review Date: Wed, Oct 5, 2022
Summary of paper
https://arxiv.org/pdf/2209.07550.pdf
Motivation
- Agent 57 came at the cost of poor data-efficiency , requiring nearly 80,000 million frames of experience to achieve.
- this one can achieve the same performance in 390 million frames
Contribution
Some key terms
NFNet - Normalisation Free Network
- https://towardsdatascience.com/nfnets-explained-deepminds-new-state-of-the-art-image-classifier-10430c8599ee
- Batch normalisation – the bad
- it is expensive
- batch normalisation breaks the assumption of data independence
- NFNet applies 3 different techniques:
- Modified residual branches and convolutions with Scaled Weight standardisation
- Adaptive Gradient Clipping
- Architecture optimisation for improved accuracy and training speed.
- https://github.com/vballoli/nfnets-pytorch
Previous Non-Image features

New features
A1. Bootstrapping with online network
- target networks are frequently used in conjunction with value-based agents due to their stabilising effect, but this design choice places a fundamental restriction on how quickly changes in the Q-function are able to propagate.
- but if we update the target more frequently, then it is no more stable
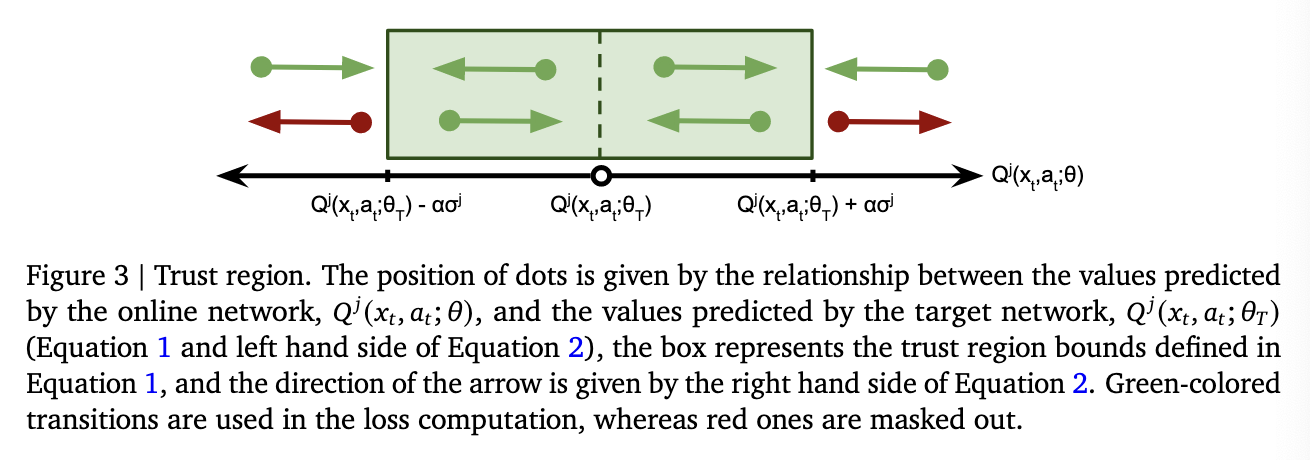
- so they use online network bootstrapping, and they stabilise the learning by introducing an approximate trust region for value updates that allows us to filter which samples contribute the loss.
- The trust region masks out the loss at any timestep for which both the following condition hold:
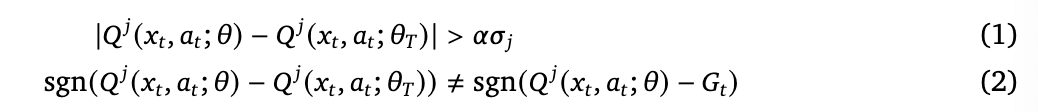
- this is similar to PPO
A2. Target computation with tolerance
- Agent57 uses Rtrace (Similar to Vtrace) to compute return estimate from off-policy data, but they observed that it tends to cut traces too aggressively when using e-greedy policy thus slowing down the propagation of information into the value function
- so the new return estimater is
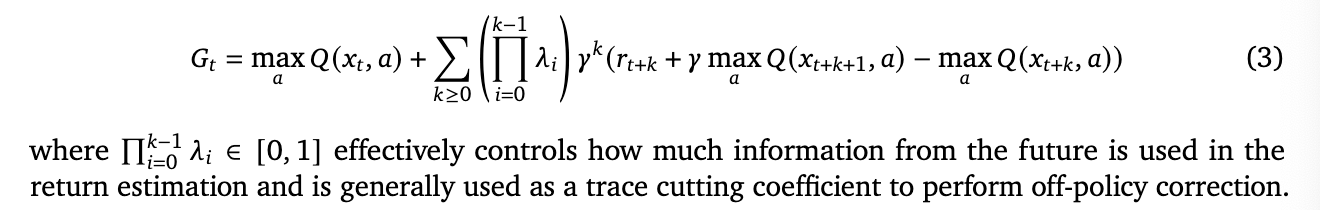
B1. Loss and priority normalisation
**B2. Cross-mixture training. **
- train all the policy network (distributed RL) rather than single policy network to increase efficiency
C1. Normalizer-free torso network
- use NFNet architecture
C2. shared torso with combined loss
- intrinsic and extrinsic components are going to use shared network
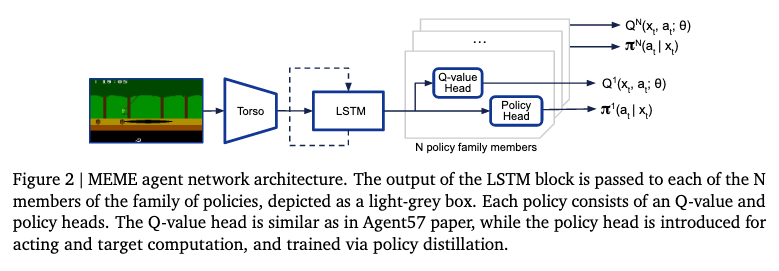
D. Robustifying behaviour via policy distillation

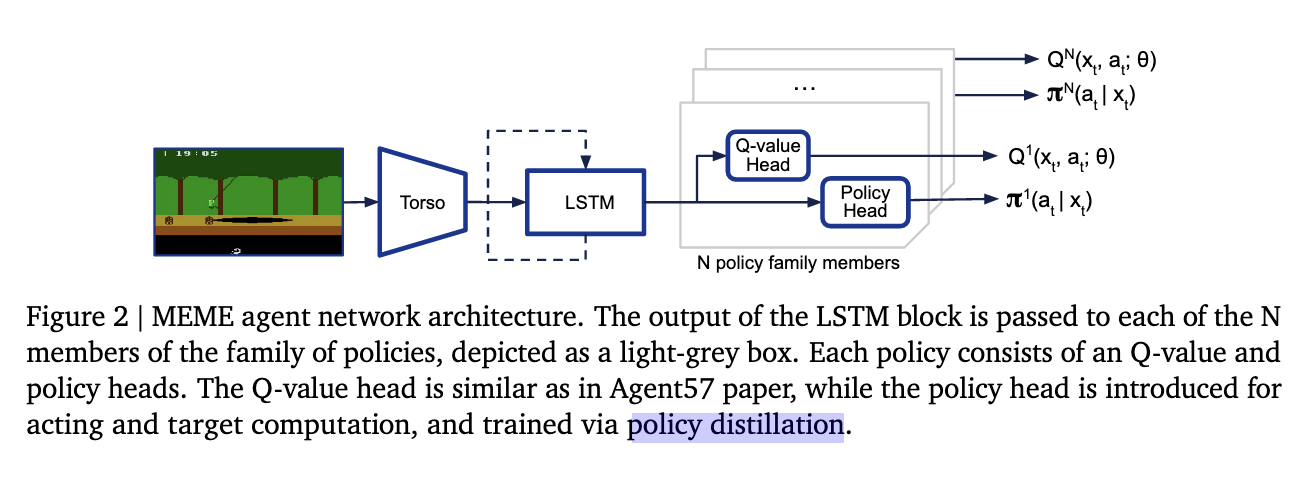
- they proposed to train an explicit policy head $\pi_{\text{dist}}$ via policy distillation to match the e-greedy policy induced by the Q-function (since it is value-based RL so the policy is just a greedy policy)