[TOC]
- Title: Teaching Models to Express Their Uncertainty in Words
- Author: Stephanie Lin et. al.
- Publish Year: 13 Jun 2022
- Review Date: Wed, Feb 28, 2024
- url: https://arxiv.org/pdf/2205.14334.pdf
Summary of paper

Motivation
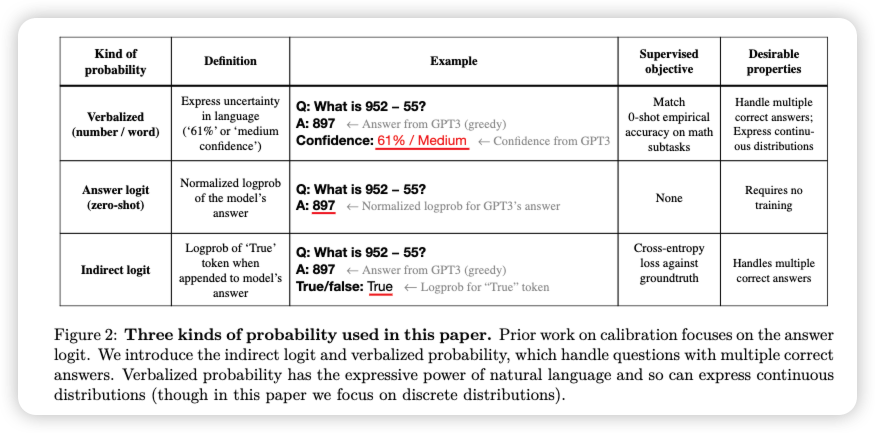
The study demonstrates that a GPT-3 model can articulate uncertainty about its answers in natural language without relying on model logits. It generates both an answer and a confidence level (e.g., “90% confidence” or “high confidence”), which map to well-calibrated probabilities. The model maintains moderate calibration even under distribution shift and shows sensitivity to uncertainty in its answers rather than mimicking human examples.
Contribution
- Introduction of CalibratedMath, a test suite comprising elementary mathematics problems where models must provide both numerical answers and confidence levels in their answers. This allows testing of calibration under distribution shifts and presents a challenging assessment due to varying question types and difficulties for GPT-3.
- Demonstration that GPT-3 can learn to express calibrated uncertainty using verbalized probabilities, achieved through fine-tuning. The model exhibits reasonable calibration both in- and out-of-distribution, surpassing a strong baseline.
- Evidence that the calibration performance of verbalized probability is not solely dependent on learning to output logits, as GPT-3 does not merely replicate uncertainty information from logits. Superficial heuristics, like integer size in arithmetic questions, cannot fully explain the performance of verbalized probability.
- Comparison between verbalized probability and finetuning the model logits, showing that both methods generalize calibration under distribution shift.
Finetuning
The supervised fine-tuning dataset consists of approximately 10k examples,
Results
-
Verbalized probability generalizes well to both eval sets After finetuning on the Add-subtract training set, verbalized probabilities generalize reason- ably well to both the Multiply-divide and Multi-answer evaluation sets. So the model remains moderately calibrated under a substantial distribution shift.
-
we have already seen that verbalized probability generalizes better than the answer logit on the Multi-answer evaluation.
-
Notably, the 50-shot approach achieves calibration levels nearly comparable to the finetuned setup.
Potential future work
Notably, the 50-shot approach achieves calibration levels nearly comparable to the finetuned setup.