[TOC]
- Title: Unifying Structure Reasoning and Language Model Pre Training for Complex Reasoning
- Author: Siyuan Wang et. al.
- Publish Year: 21 Jan 2023
- Review Date: Wed, Feb 8, 2023
- url: https://arxiv.org/pdf/2301.08913.pdf
Summary of paper

Motivation
- language models still suffer from a heterogeneous information alignment problem and a noisy knowledge injection problem.
- for complex reasoning, the context contains rich knowledge that typically exists in complex and sparse form.
Contribution
- we propose to unify structure reasoning and language model pre-training
- identifies four types of elementary knowledge structures from contexts to construct structured queries
- utilise box embedding method to conduct explicit structure reasoning along query during language modeling
Some key terms
What is the problem
- using context information to avoid two problems, namely, the semantic gap between two domains and noisy knowledge introduced by retrieval.
model
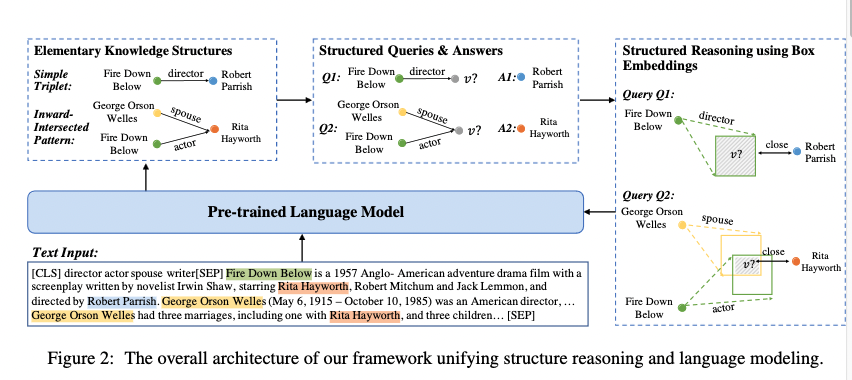
- in specific, our model starts with extracting knowledge structures from the context and constructs the structured queries with the answer entity
- question: how to ensure the accuracy???
- Representations of query structure and the answer are learned via box embedding (Ren et. al. 2020)
- The training process mains to put the answer embedding inside the query box embedding in the semantic space.
Knowledge Structures Identification
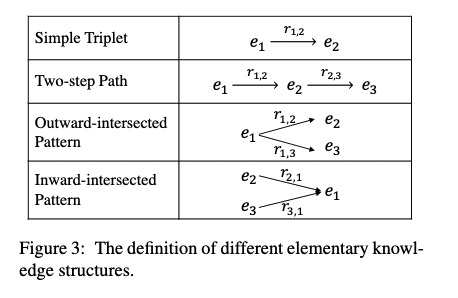
- we propose four types of elementary knowledge structures for reasoning over both simple and complex knowledge in the text as shown in Figure 3.
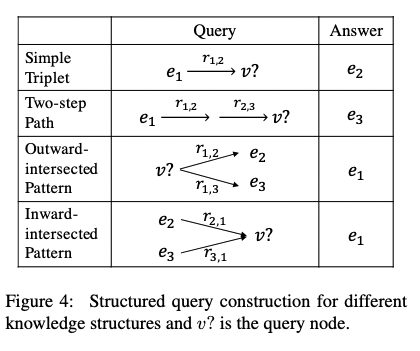
Box embedding

Pretraining
- we jointly optimize structure reasoning and language modelling to obtain a unified structure embedded language representation.
- the overall pre-training objective is the combination of the structure reasoning loss $L_{SR}$ and the masked language modelling loss $L_{LML}$
- we utilise Wikipedia documents with entities and their relation constructed by (Qin et. al. 2020) to obtain knowledge structures for pre-training.