[TOC]
- Title: Distilling Script Knowledge From Large Language Models for Constrainted Language Planning
- Author: Siyu Yuan et. al.
- Publish Year: 18 May 2023
- Review Date: Mon, May 22, 2023
- url: https://arxiv.org/pdf/2305.05252.pdf
Summary of paper
Motivation
- to accomplish everyday goals, human usually plan their actions in accordance with step-by-step instructions, such instruction are discovered as goal-oriented scripts.
- In this paper, we define the task of constrained language planning for the first time. We propose an over-generate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts.
Contribution
- the dataset
- Experiments show that, when trained on CoScript, smaller models such as T5 (Raffel et al., 2020) can achieve good performance, even surpassing that of LLMs
Some key terms
limitation of previous work
- Our empirical study finds that LLMs tend to plan fluently but unfaithfully to the constraints.
methodology
- Thus, we employ an over-generate-then-filter approach (Wiegreffe et al., 2022) to satisfy the quality of the generated scripts to constraints.
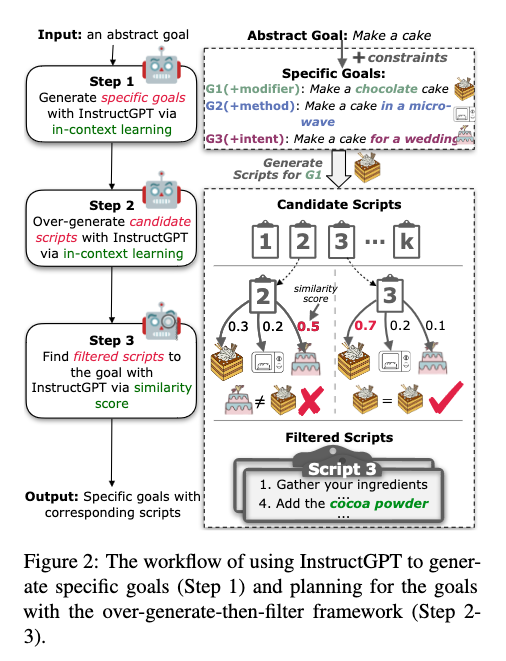
Filtering process
- due to the diverse expressions of language, we rely not on rules and patterns, but on the semantic similarity between goals and scripts for filtering.
- we first collect a set of goals, consisting of the target goal as positive sample and others generated from the same abstract goal (they are hard negatives then). we convert scripts and goals into instructGPT embeddings (text-embedding-ada-002) and calculate cosine similarity as similarity scores to measure semantic similarity.
- we only keep the script if the the positive pairs scores the highest in the goal set.
- Assumption: the corresponding goal and script embeddings should be similar.
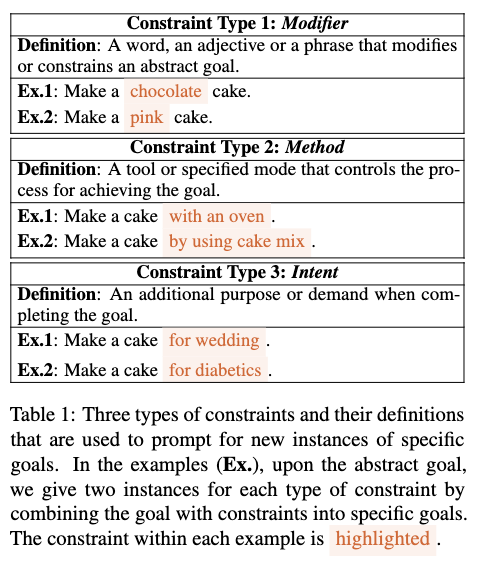
types of constraints (definition)

Good things about the paper (one paragraph)
Major comments
- it releases Coscript dataset

Potential future work
- over-generate-then-filter approach might be a good way for LLMs