[TOC]
- Title: Language-Driven Representation Learning for Robotics
- Author: Siddharth Karamcheti et. al.
- Publish Year: 24 Feb 2023
- Review Date: Fri, Mar 3, 2023
- url: https://arxiv.org/pdf/2302.12766.pdf
Summary of paper
Motivation
- recent work in visual representation learning for robotics demonstrates the viability of learning from large video datasets of humans performing everyday tasks.
- leveraging methods such as masked autoencoding and contrastive learning, these representations exhibit strong transfer to policy learning for visuomotor control
- but robot learning encompasses a diverse set of problems beyond control including grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration amongst others.
Contribution
- first, we demonstrate that existing representations yield inconsistent results across these tasks: masked autoencoding approaches pick up on low-level spatial features at the cost of high-level semantics, while contrastive learning approaches capture the opposite (i.e., high-level semantics)
- We then introduce Voltron, a framework for language driven representation learning from human videos and associated captions.
- Voltron trades off language conditioned visual reconstruction to learn low-level visual patterns (mask auto-encoding) and visually grounded language generation to encode high-level semantics. (hindsight relabelling and contrastive learning)
Some key terms
How can we learn visual representations that generalise across the diverse spectrum of problems in robot learning?
- recent approaches for learning visual representations for robotics use pretraining objectives that reflect different inductive biases for what the learned representations should capture.
- Masked Visual Pretraining proposes using masked autoencoding to prioritise visual reconstruction from heavily masked video frames, encoding representations that facilitate per-pixel reconstruction
- Separately, resusable representations for robotic manipulation eschews pixel reconstruction for two contrastive learning objectives: time contrastive learning and video language alignment (hindsight relabeling, phrase corruption)
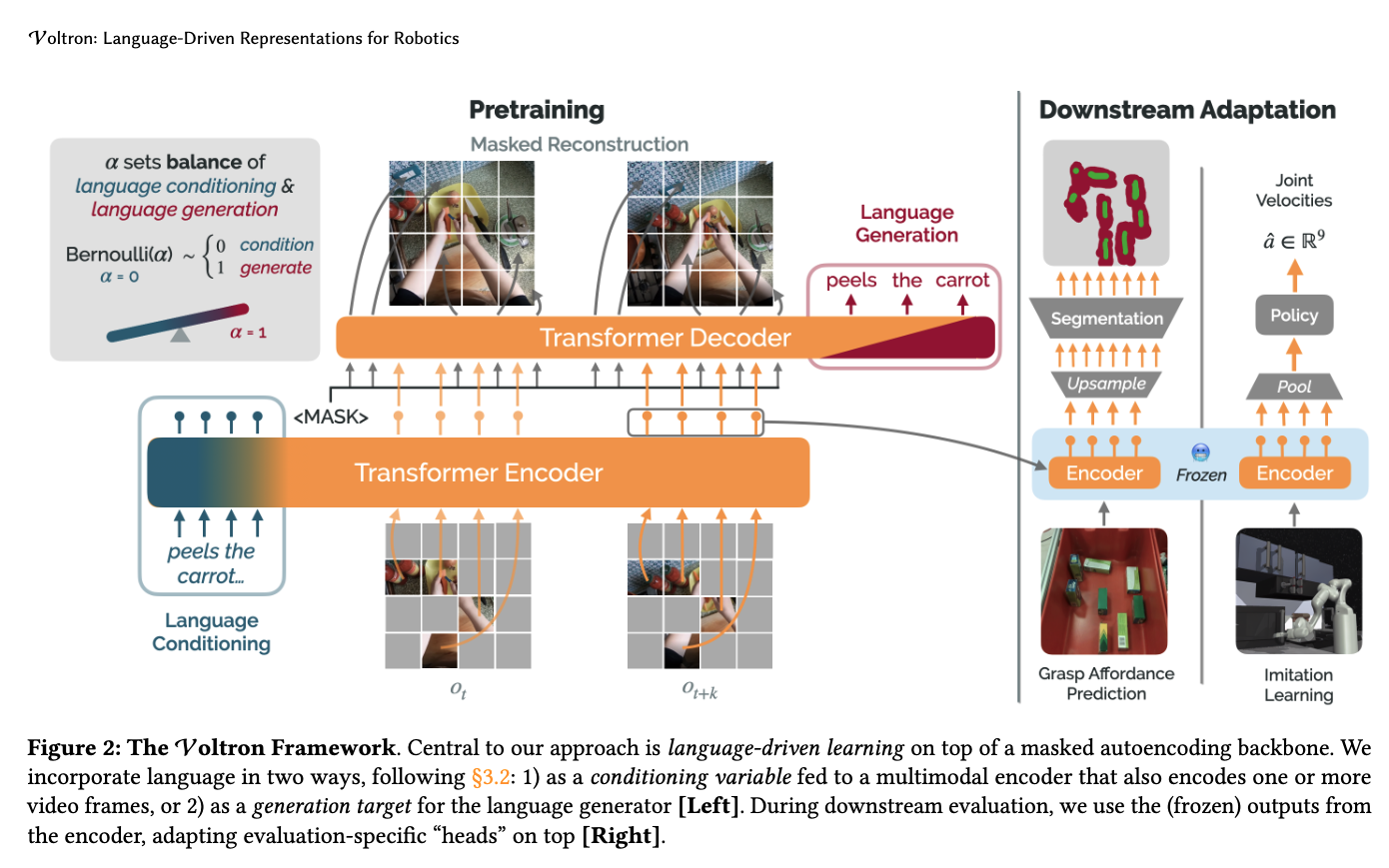
Voltron Framework

- central to our approach is language-driven learning on top of a masked autoencoding backbone.
- We sample a mask once, and apply it uniformly across all frames in the video to prevent leakage (in video)
- A Voltron model comprises
- a multimodal encoder that takes in a visual context and (optional) language utterance producing a dense representation
- a visual reconstructor that attempts to reconstruct the masked-out visual context from the encoder’s representation of what is visible and
- a language generator that predicts the language annotation for the video given the encoded visual context.
when can we focus on the high-level semantic features
- when we favour language generation, we need the ability to comprehend high-level semantic features.
- what is $\alpha$ balance of language conditioning & language generation
- for each video caption pairs (v,c) seen at training, we draw $z \sim Bernoulli(\alpha)$ with $z=0$ we condition on the original language utterance, while $z=1$ we generate the original language utterance, conditioning in the encoder on the <NULL> token.

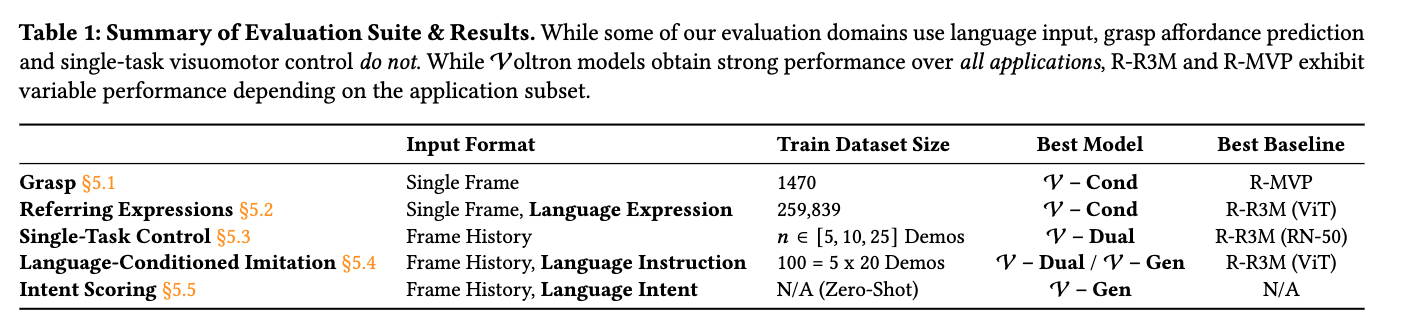
Results
Potential future work
- it seems that we can utilise the method mentioned in this paper for our project
- pretraining the model using video caption dataset
- something-something-v2 dataset