[TOC]
- Title: Shailaja_keyur_sampat Reasoning About Actions Over Visual and Linguistic Modalities a Survey 2022
- Author:
- Publish Year:
- Review Date: Fri, Jan 20, 2023
Summary of paper

Motivation
- reasoning about actions & changes has been widely studies in the knowledge representation community, it has recently piqued the interest of NLP and computer vision researchers.
Contribution
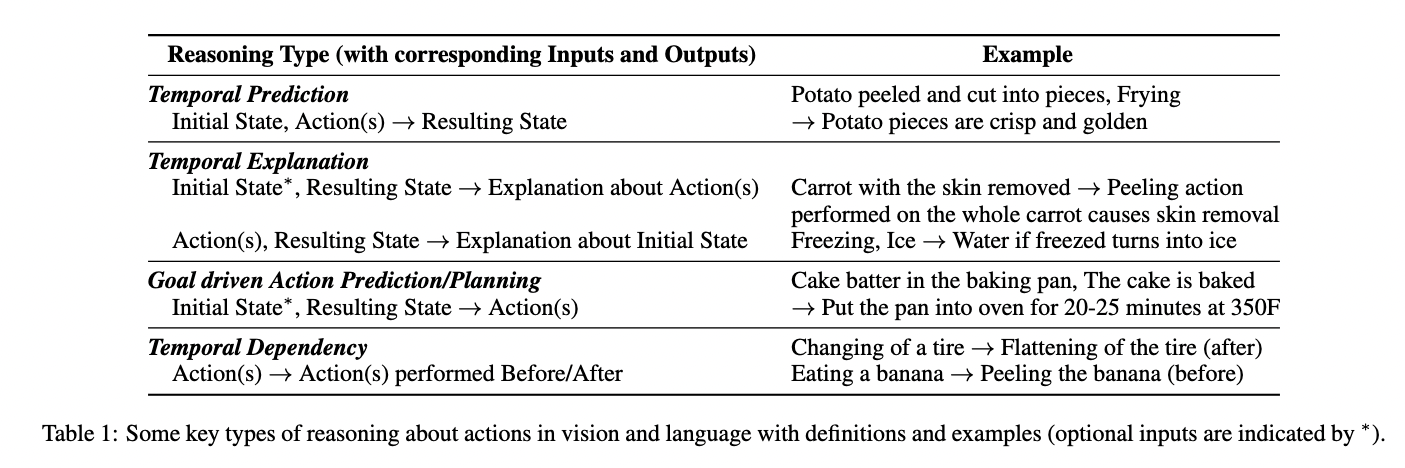
Some key terms
Six most frequent types of commonsense knowledge
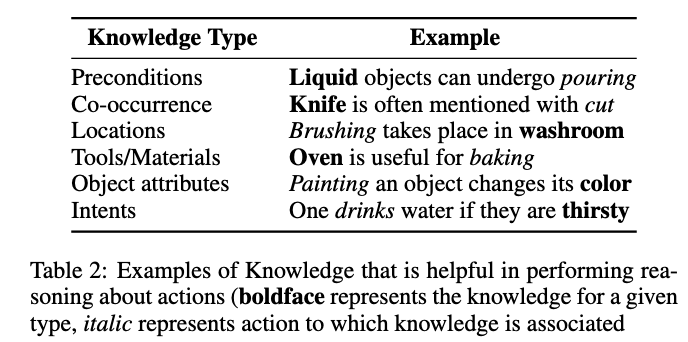
tasks that involve language-based reasoning about actions
- Pure language based tasks are suitable when high-level goal descriptions are to be mapped with a set of actions or for explainability purposes i.e. to provide justification about the choice of action or commonsense knowledge that is useful to make conclusions.
- as states become more complicated and involve many different objects, it becomes hard to convey every single detail (about object’s position, attributes such as colors, size, texture, etc) through text and require complex description to refer to objects to avoid possible ambiguity.
Role of multi-modality
- multi-modal learning aims to build models that can process and relate information from two or more modalities. Image-text multimodality has received significant interest in AI community recently as it is an important skill for humans to perform day to day tasks. Perception systems can be leveraged to identify variety of visual information and a concise way to learn through observations i.e. learn to identify or perform actions. On the other hand, language provides an effective way to exchange thoughts, communicate, query or provide justifications e.g., explaining the choice of actions while performing a task or highlighting preconditions or commonsense before performing actions. Thus multi-modal context play an important role in understanding actions and reasoning about them. The presence of multiple modalities provide natural flexibility for varied inference tasks.
Instruction following
- language guided image manipulation is an emerging research direction in vision+language. While a majority of dataset involve object and attribute level scene manipulations, ….
- Another relevant task under this category is vision-and-language navigation, where an agent navigates in a visual environment to find a goal location by following linguistic instructions. All the above datasets include visuals, natural language instructions and a set of actions that can be performed to achieve desired goals. Further, ALFRED increased the complexity of level of the VLN task for agents by adding long, compositional tasks. The task comprises of dealing with longer action sequences, complex action space, and language that are closely related to real-world situations.
Good things about the paper (one paragraph)
Major comments
Minor comments
Citation
- As a result, a significant amount of commonsense knowledge we use in our day to day life resolves around actions.
- reasoning about actions is important for humans as it helps us to predict if a sequence of actions will lead us to achieve the desired goal.
- the ability of artificial agents to perform reasoning and integrate commonsense knowledge about actions is highly desirable.
- In over four decades of research, the knowledge representation and reasoning (KR&R) community has been successful in developing promising solutions to Reasoning Action and Change (RAC) problems.
- ref: Sampat, Shailaja Keyur, et al. “Reasoning about actions over visual and linguistic modalities: A survey.” arXiv preprint arXiv:2207.07568 (2022).