[TOC]
- Title: Improving language models by retrieving from trillions of tokens
- Author: Sebastian Borgeaud et. al.
- Publish Year: Feb 2022
- Review Date: Mar 2022
Summary of paper
Motivation
in order to decrease the size of language model, this work suggested retrieval from a large text database as a complementary path to scaling language models.
they equip models with the ability to directly access a large dataset to perform prediction – a semi-parametric approach.
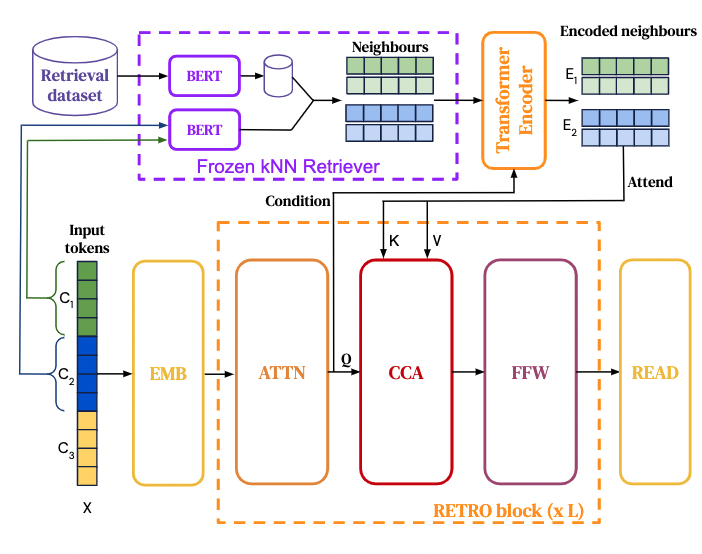
how do they do
first, construct a key-value database, where values store raw chunks of text tokens and key are frozen BERT embeddings.
- then we use a frozen model (not trainable) to avoid having to periodically re-compute embeddings over the entire database during training.
second, each training sequence input is split into chunks, which are augmented with their k-nearest neighbours retrieved from the database.
- e.g.,
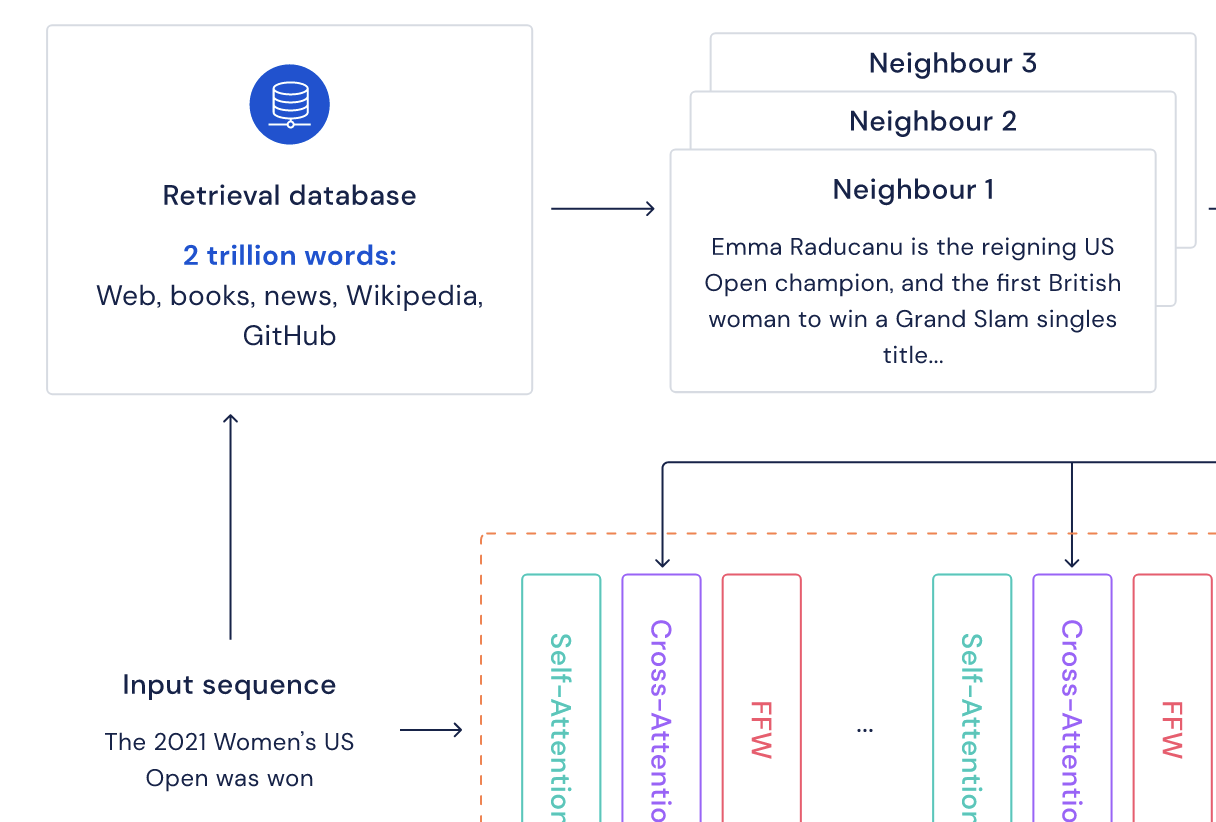
- so a chunk C1 will have several value neighbours from the database.
finally, a encoder-decoder architecture integrates retrieval chunks into the models’s predictions.
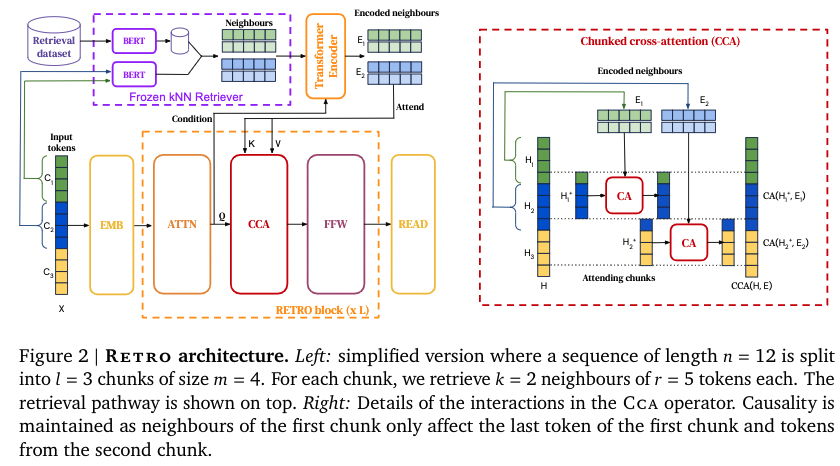
- check the CCA architecture, this preserves autoregressivity, the later token depends on the previous tokens.
- FFW is the fully connected layer
- ATTN is self attention module
Algorithm

Some key terms
retrieval database
a key-value database
- where values store raw chunks of text tokens and key are frozen BERT embeddings query keys
- two main approaches are matching words in the query against the database index (keyword searching) and traversing the database using hypertext or hypermedia links
- in this work, the value of the database is some information sentences
-

Potential future work
looks like we do have such a very large database
also the database input and output are both text sequences, which may not be useful for language assisted RL