[TOC]
- Title: Building Goal Oriented Dialogue Systems With Situated Visual Context 2021
- Author: Sanchit Agarwal et. al.
- Publish Year: 22 Nov 2021
- Review Date: Sun, Nov 20, 2022
Summary of paper
Motivation
- with the surge of virtual assistants with screen, the next generation of agents are required to also understand screen context in order to provide a proper interactive experience, and better understand users’ goals.
- So in this paper, they propose a novel multimodal conversational framework, where the agent’s next action and their arguments are derived jointly conditioned on the conversational and the visual context.
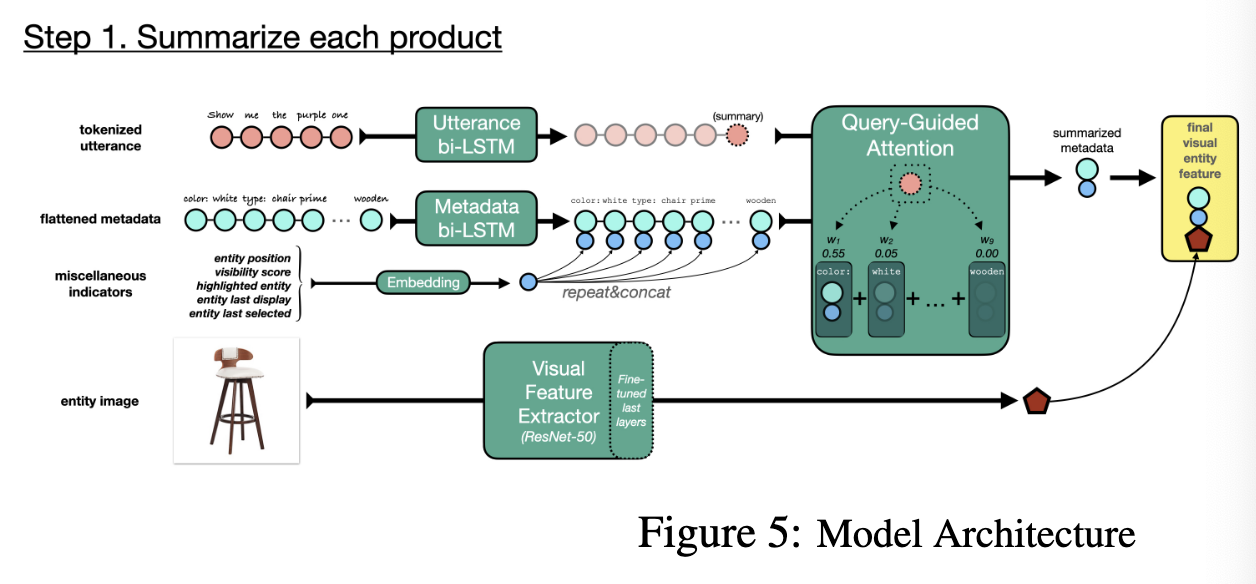
- The model can recognise visual features such as color and shape as well as the metadata based features such as price or star rating associated with a visual entity.
Contribution
- propose a novel multimodal conversational system that considers screen context, in addition to dialogue context, while deciding the agent’s next action
- The proposed visual grounding model takes both metadata and images as input allowing it to reason over metadata and visual information
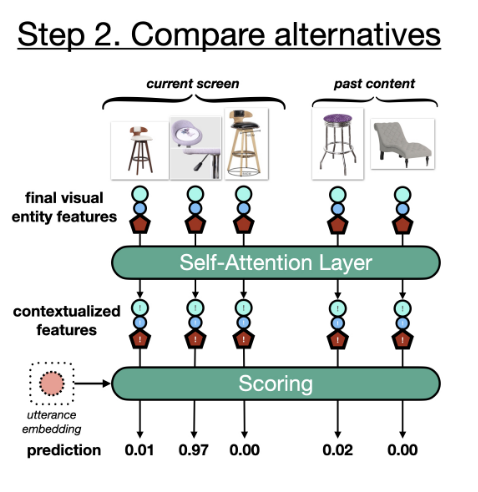
- Our solution encodes the user query and each visual entities and then compute the similarity between them. to improve the visual entity encoding, they introduced query guided attention and entity self-attention layers.
- collect the MTurk survey and also create a multimodal dialogue simulator
Architecture