
[TOC]
- Title: Secrets of RLHF in Large Language Models Part1: PPO
- Author: Rui Zheng et. al.
- Publish Year: 18 Jul 2023
- Review Date: Mon, Jan 22, 2024
- url: arXiv:2307.04964v2
Summary of paper
Motivation
- Current approaches involve creating reward models to measure human preferences, using Proximal Policy Optimization (PPO) to improve policy models, and enhancing step-by-step reasoning through process supervision. However, challenges in reward design, interaction with the environment, and agent training, along with the high trial and error costs of LLMs, make it difficult for researchers to develop technically aligned and safe LLMs.
Contribution
- finding that LLMs trained using their algorithm can better understand query meanings and provide responses that resonate with people.
- A new PPO algorithm called PPO-max is introduced, which incorporates effective implementations and addresses stability issues.
Some key terms
RLHF limitation
- Reinforcement Learning with Human Feedback (RLHF) has been identified as a valid approach, but it is challenging to train LLMs effectively with it due to issues like reward model quality and inefficient exploration in word space.
RLHF in one paragraph
- Reinforcement Learning (RL) is a promising solution, where agents learn human preferences through a reward model and undergo numerous trials under RLHF (Reinforcement Learning from Human Feedback). Several recent attempts have been made in this direction.
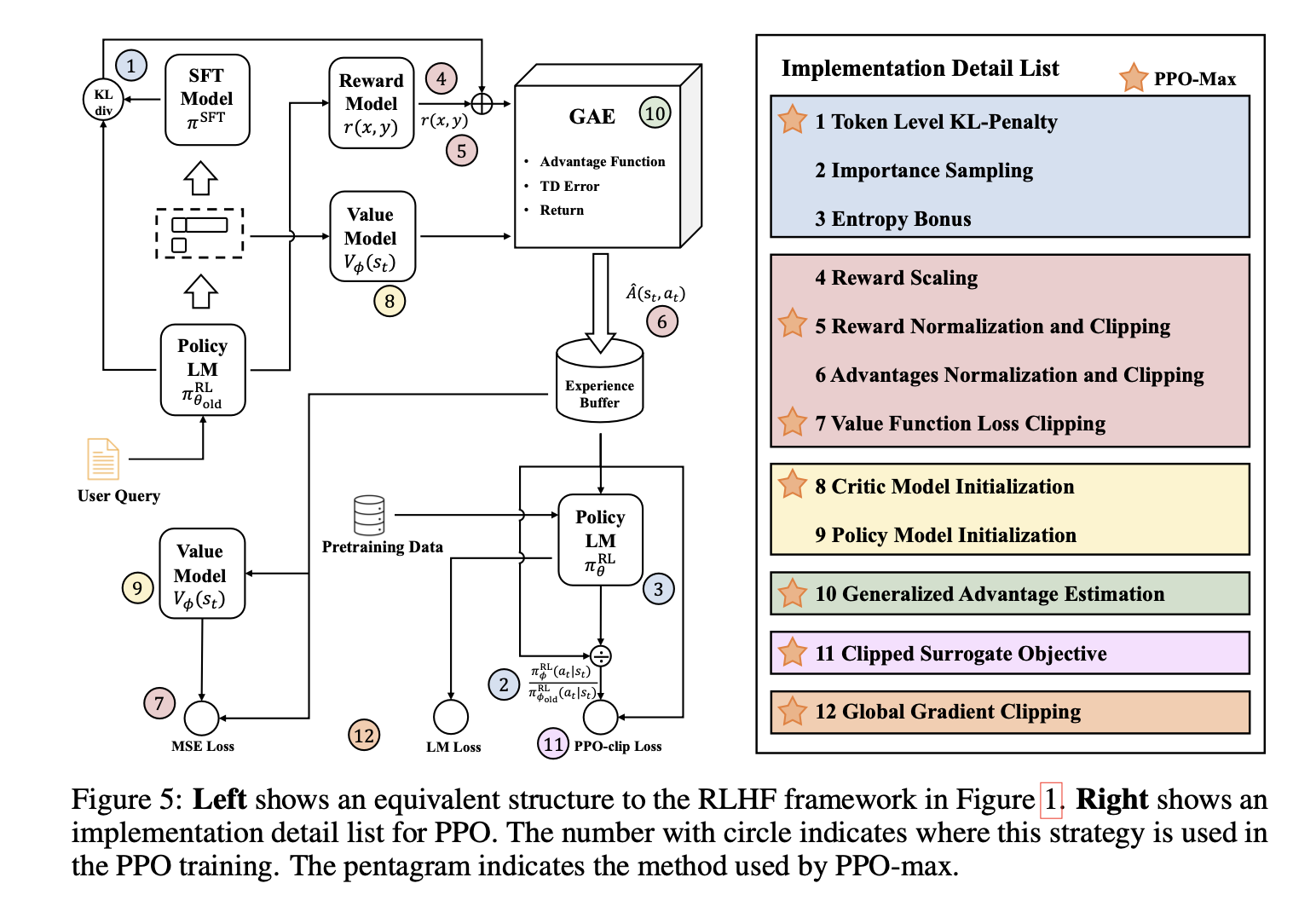
- The training process of an AI assistant involves three primary stages: supervised fine-tuning (SFT), reward model (RM) training, and proximal policy optimization (PPO).
- In the SFT phase, the model learns to engage in human-like dialogues by imitating examples provided in human-annotated dialogue data.
- The RM training phase focuses on training the reward model. In this stage, the model learns to evaluate and compare the preference of different responses based on human feedback. This feedback is crucial for guiding the model towards producing more desirable and aligned responses.
- The final phase is PPO, where the model is updated based on the feedback obtained from the trained reward model. PPO aims to discover an optimized policy by balancing exploration and exploitation, ensuring that the model’s responses align with human preferences.
Helpfulness
- Helpfulness means the model should follow instructions; it must not only follow instructions but also deduce the intent from a few-shot prompt or another interpretable pattern. However, the intention behind a given prompt can often be unclear or ambiguous, which is why we depend on our annotators’ judgment, and their preference ratings constitute our primary metric.
Alignment metrics
- Alignment is a vague and confusing topic that is intractable to evaluate. In the context of our paper, we endeavor to align models with human intentions. To be more specific, we define models to act as being helpful and harmless similar to [27]
Results
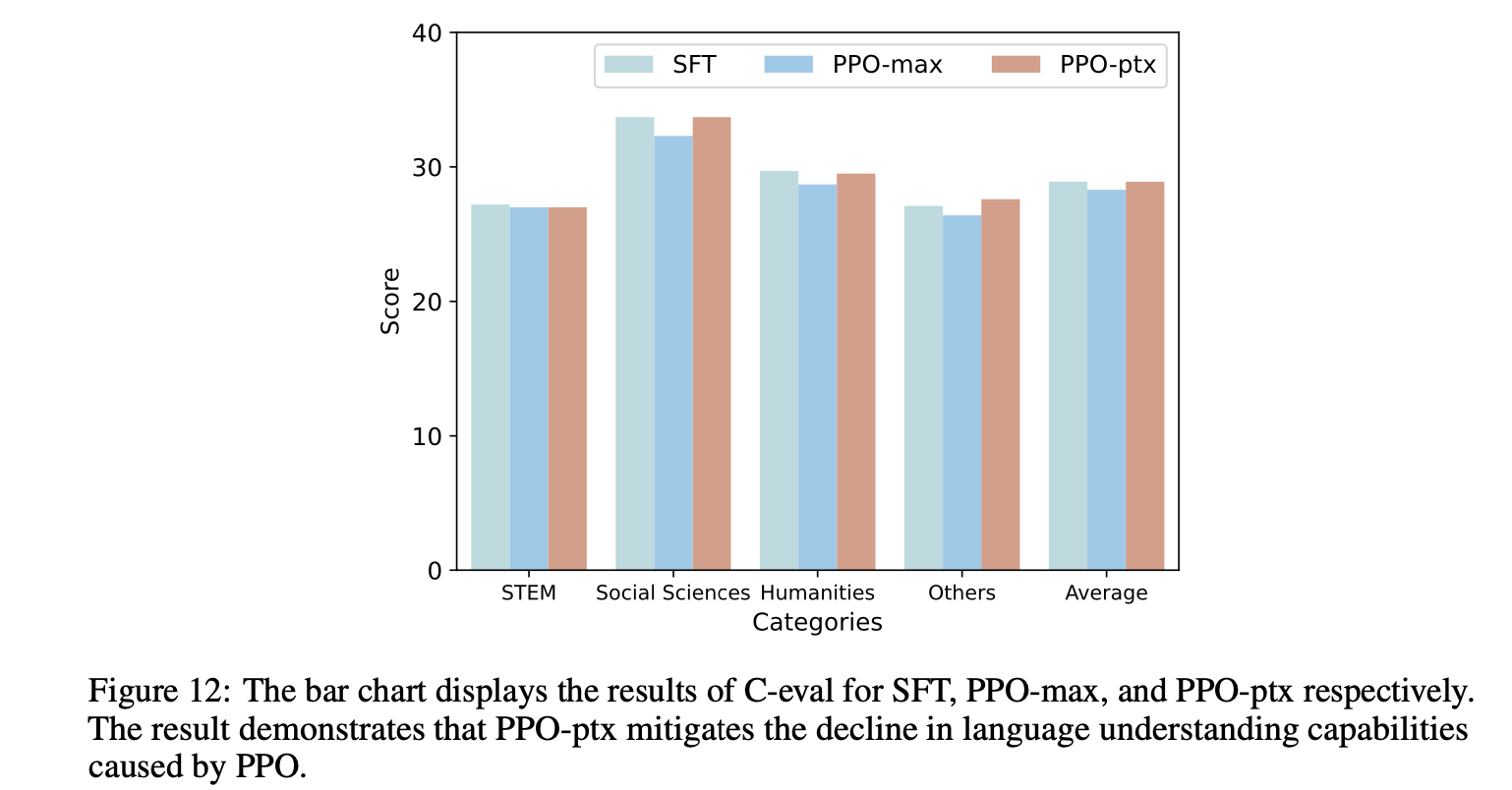
- there will be decline in language understanding capabilities caused by PPO.
Summary
the paper summarized a bunch of implementation details for the PPO training