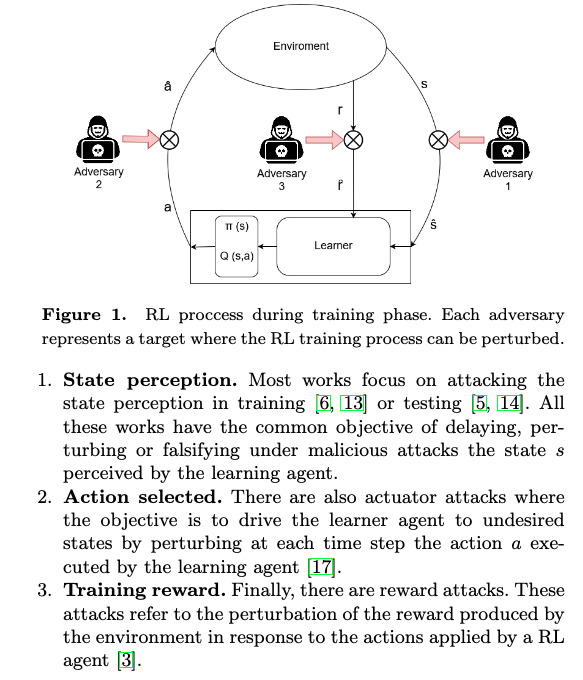
[TOC]
- Title: Disturbing Reinforcement Learning Agents With Corrupted Rewards
- Author: Ruben Majadas et. al.
- Publish Year: Feb 2021
- Review Date: Sat, Dec 17, 2022
Summary of paper
Motivation
- recent works have shown how the performance of RL algorithm decreases under the influence of soft changes in the reward function.
- However, little work has been done about how sensitive these disturbances are depending on the aggressiveness of the attack and the learning learning exploration strategy.
- it chooses a subclass of MDPs: episodic, stochastic goal-only rewards MDPs
Contribution
- it demonstrated that smoothly crafting adversarial rewards are able to mislead the learner
- the policy that is learned using low exploration probability values is more robust to corrupt rewards.
- (though this conclusion seems valid only for the proposed experiment setting)
- the agent is completely lost with attack probabilities higher that than p=0.4
Some key terms
deterministic goal only reward MDP
- a reward is only given if a goal state is reached.
- many decision task are modelled with goal-only rewards from classical control problems such as Mountain Car or the Cart Pole
- the goal only reward setting is a special case for sparse reward setting.
goal of adversary
- produce the maximum deterioration in the learner policy performing the minimum number of attacks.
Major comments
citation
- the attack on reward function has received very little attention
- ref: Majadas, Rubén, Javier García, and Fernando Fernández. “Disturbing reinforcement learning agents with corrupted rewards.” arXiv preprint arXiv:2102.06587 (2021).
- ref: Jingkang Wang, Yang Liu, and Bo Li, ‘Reinforcement learning with perturbed rewards’, CoRR, abs/1810.01032, (2018)
- there are no studies about how sensitive the learning process is depending on the aggressiveness of reward perturbations and the exploration strategy.
- ref: Majadas, Rubén, Javier García, and Fernando Fernández. “Disturbing reinforcement learning agents with corrupted rewards.” arXiv preprint arXiv:2102.06587 (2021).
limitation on the setting
- this consider with small and low-dimensional state space
- lack the consideration of sparse reward setting with high dimensional large state space
- this perturbation is based on the probability and lack the focus on the false positive rewards.
- the perturbation is limited to only changing the sign of the true rewards.
- A fixed attack probability was used in the experiments to test how reward attacks affect agents with varying exploration rates.
- this experiment is like punish the good movements that lead to the goal.