[TOC]
- Title: Reward Machines for High Level Task Specification and Decomposition in Reinforcement Learning
- Author: Rodrigo Toro Icarte et. al.
- Publish Year: PMLR 2018
- Review Date: Thu, Aug 17, 2023
- url: http://proceedings.mlr.press/v80/icarte18a/icarte18a.pdf
Summary of paper

Motivation
- proposing a reward machine while exposing reward function structure to the learner and supporting decomposition.
Contribution
- in contrast to hierarchical RL methods which might converge to suboptimal policies. We prove that QRM is guaranteed to converge to an optimal policy in the tabular case.
Some key terms
intro
- there is less reason to hide the reward function from the agent.
- this work our method is able to reward behaviours to varying degrees in manners that cannot be expressed by previous approaches.
- i.e., reward the behaviours in advanced way
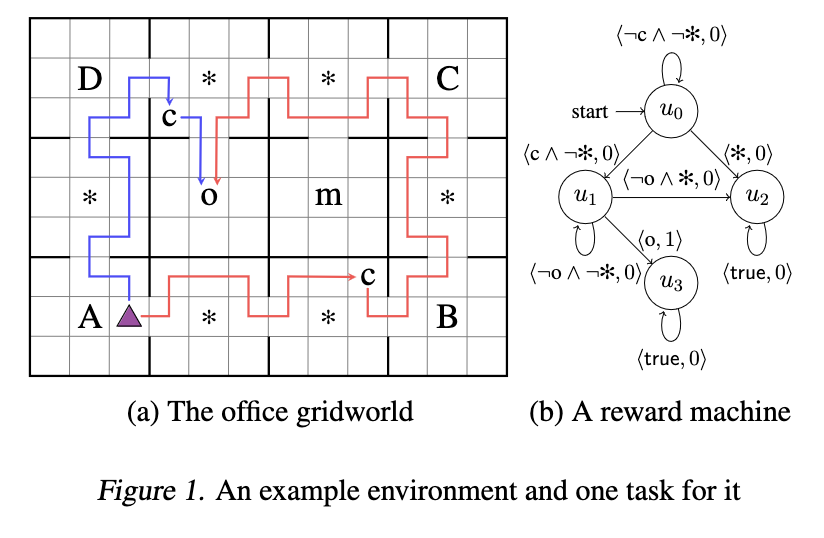
reward machine
- a RM allows for composing different reward functions in flexible ways, including concatenations, loops and conditional rules.
- after every transition, the reward machine output the reward function the agent should use at that time.
- the author claim that the structure of RM can give agent knowledge that the problem consists of multiple stages and thus can use the information to decompose the task.
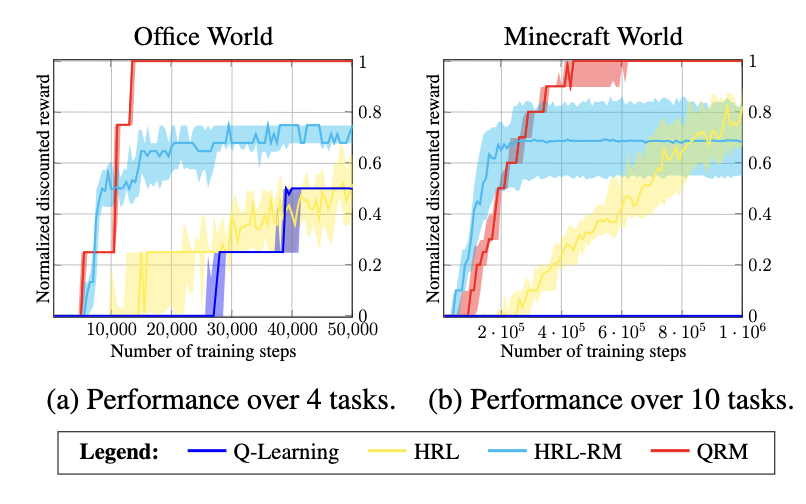
Q-learning for reward machines (QRM)
- can exploit a reward machine’s internal structure to decompose the problem and thereby improving sample efficiency.
- it uses q learning to update each sub-task policy in parallel.
- we show that QRM is guaranteed to converge to an optimal policy in the tabular case.
Bellman equation

Reward machine for task specification
- The intuition is that the agent will be rewarded by different reward functions at different times, depending on the transitions made in the RM.
definition of reward machine

- definition of simple reward machine
- the reward only relies on the internal state of RM rather than the transitions in the world.
- Limitation
- the RM has a clear understanding about the when the world state transits to their targeted high-level ones.
- a ground-truth labelling function

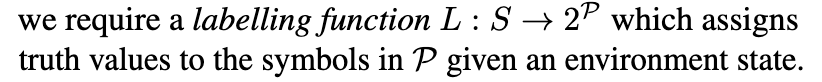
A posible solution for LRS

- we need different q functions – meaning different sub policies

Major comments
- it is still very challenging to think about how to ground this method to simulated Atari games where there is no prepared labelling function for you.