
[TOC]
- Title: Hierarchical Temporal Aware Video Language Pre Training
- Author: Qinghao Ye, Fei Huang et. al.
- Publish Year: 30 Dec 2022
- Review Date: Thu, Apr 6, 2023
- url: https://arxiv.org/pdf/2212.14546.pdf
Summary of paper

Motivation
- most previous methods directly inherit or adapt typical image-language pre-training paradigms to video-language pretraining, thus not fully exploiting the unique characteristic of video, i.e., temporal.
Contribution
- this paper, the two novel pretraining tasks for modeling cross-modal alignment between moments and texts as well as the temporal relations of video-text pairs.
- specifically, we propose a cross-modal moment exploration task to explore moments in videos, which results in detailed video moment representations
- besides, the inherent temporal relations are capture by alignment video-text pairs as a whole in different time resolutions with multimodal temporal relation exploration tasks
Some key terms
limitation of previous work
- they treat video within global perspective, thus failing to consider fine-grained temporal information and relations which are essential to video-language pre-training
- directly treating the video globally has two main limitations
- less effective in modelling the fine-grained moment information including atomic actions and moments
- so, we vary time resolution and generate two views (long and short) for the input video. As a result, the short view video clip tends to represent the moment information and the long-view video may express more event-level information
- e.g., the short view video clip only describes the moment of “lick fingers” rather than “eating ice cream”.
- ignoring the temporal relations implicitly existed in the video. Knowing the event expressed by the text, the moment “eating ice cream” can be inferred from the moment “lick fingers” shown by short-view video.
- less effective in modelling the fine-grained moment information including atomic actions and moments
METHOD
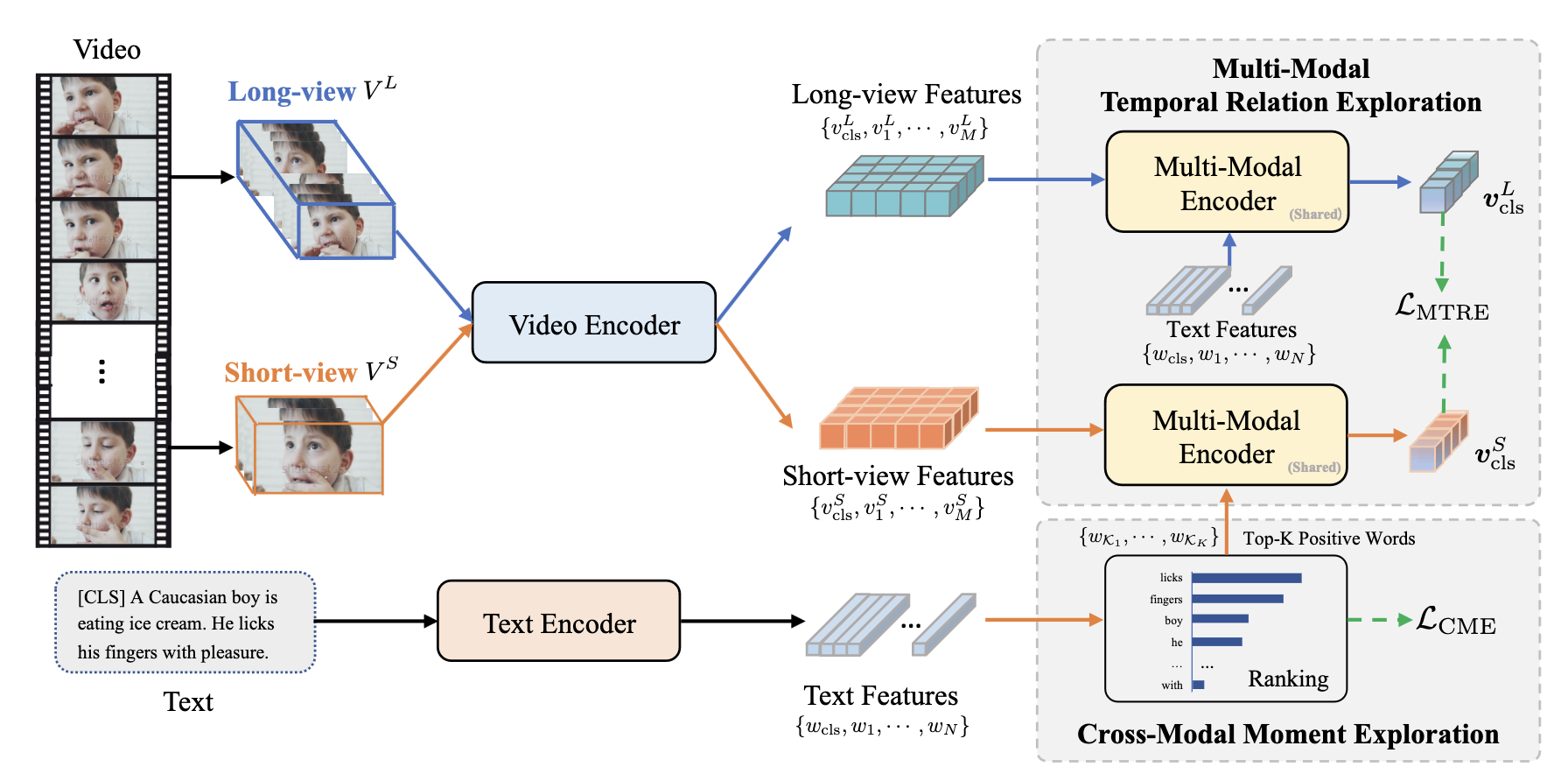
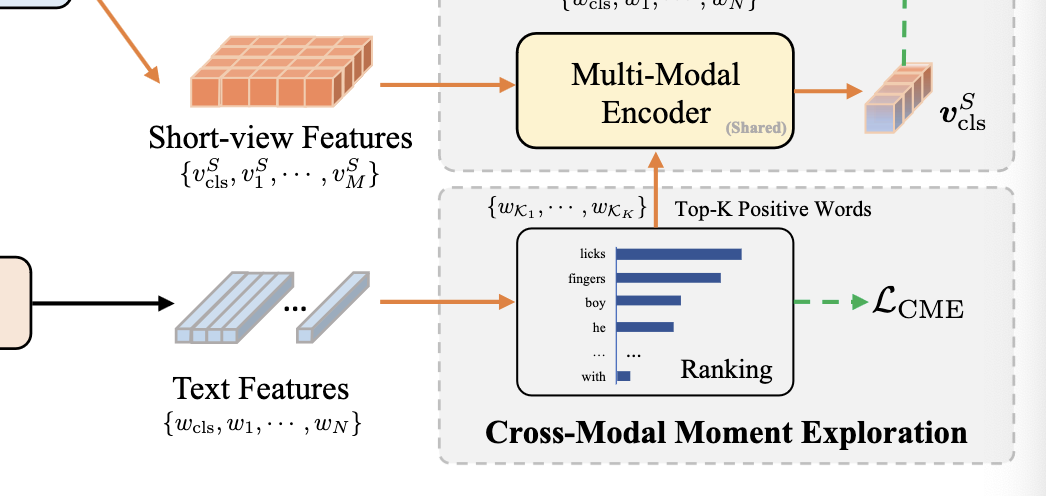
cross-modal moment exploration (CME)
- we first generate long-view and short-view videos with different time resolutions to build hierarchy of the input video.
- then, based on the similarities of words and short-view videos, we select the most relevant words as positive and leave the rest of words as hard negatives
- The CME pre-training task is applied to align the positive words and short-view video representations in the same embedding space
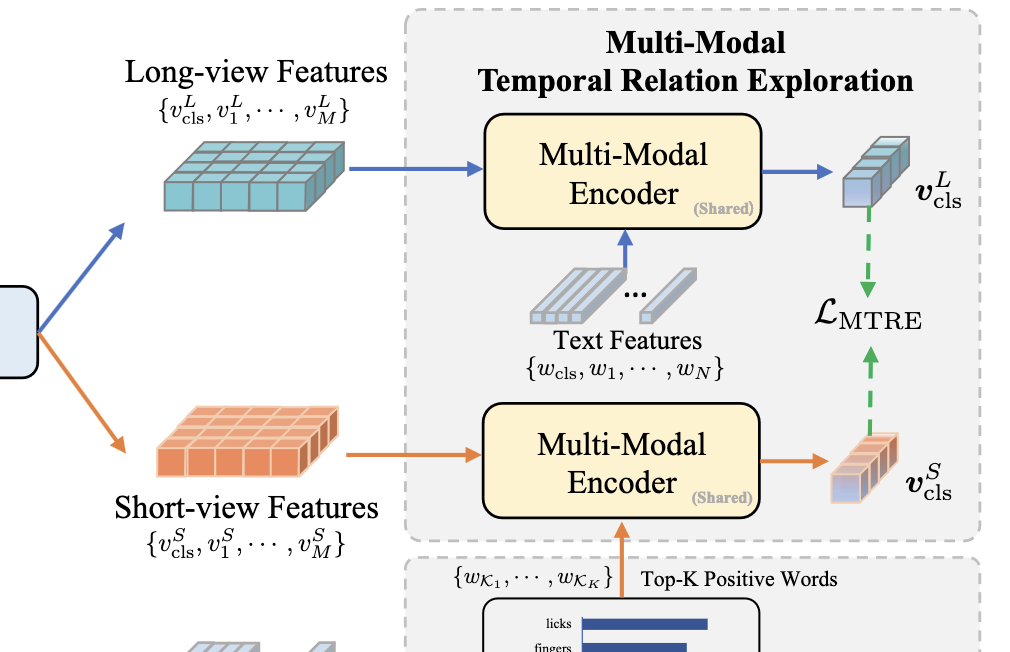
multimodal temporal exploration (MTRE)
-
to capture association between moments and the event, we match different views for the same video
- however, directly matching two views visually would be noisy due to the background similarity
-
MTRE -> the short view video guided by most relevant words and the long-view video guided by text will be aligned.
-
-

-

-
we aim to minimizing the negative cosine similarity

Potential future work
Models and demo are available on ModelScope.