[TOC]
- Title: Zero Shot Reward Specification via Grounded Natural Language
- Author: Parsa Mahnoudieh et. al.
- Publish Year: PMLR 2022
- Review Date: Sun, Jan 28, 2024
- url:
Summary of paper

Motivation
- reward signals in RL are expensive to design and often require access to the true state.
- common alternatives are usually demonstrations or goal images which can be label intensive
- on the other hand, text descriptions provide a general low-effect way of communicating.
- previous work rely on true state or labelled expert demonstration match,
- this work directly use CLIP to convert the observation to semantic embeddings
Contribution
Some key terms
Difference
- image based goal specification
- they are typicaly limited to a particular scene
- where semantic goal comprise multiple possible scene configuration NOTE: DIFFERENT MOTIVATION -> the generalisation ability for multitask
- reward functions or policies that take natural language as for goal descriptions
- they however relay on reward signals that have access to state of the system
Scope of the study
- We wish to have an agent that can learn purely from pixels, with no access to the underlying state of the environment at any point during learning or task execu- tion. Achieving this goal without access to an instrumented reward function has been exceedingly challenging.
Limitation of image based reward
- To be sure that the true goal is properly specified irrespective of the invariances of the model’s underlying perceptual representation, a user may have to provide a set of goal image examples that cover the variation of the target concept, potentially a very expensive undertaking to collect or generate.
Large scale joint embedding models
- CLIP and XCLIP
Method
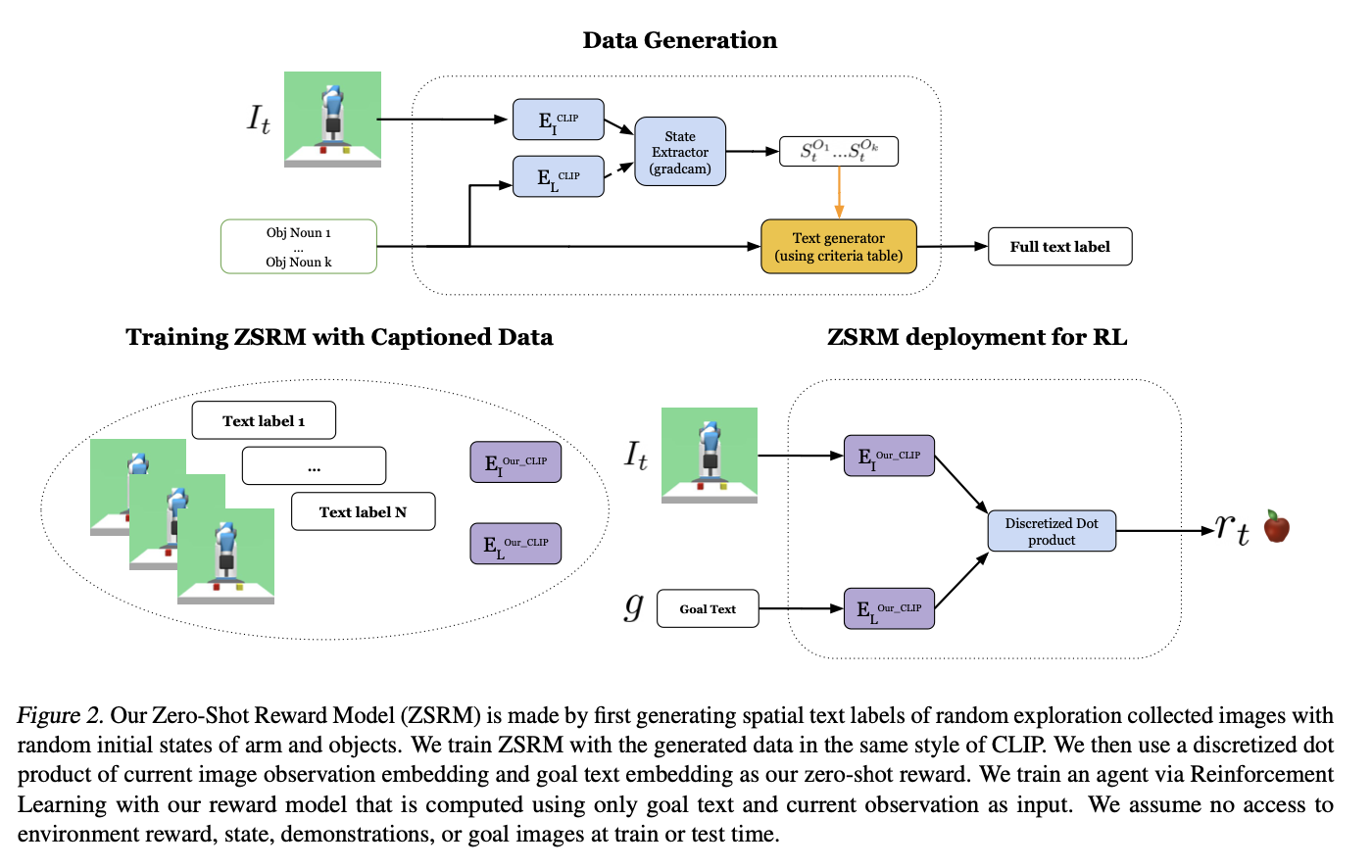
- One way to communicate text-based goal to a robot is by simply offering a description of the goal configuration in natural language and using the CLIP embedding dot product with an observed image to evaluate proximity to goal state.
- direct cosine similarity is not working for complex environment.
- a little object extraction and spatial relation text generator was created in order to create the (observation, text) pair
Generic task described by text
- text description is more generic / ambiguous compared to image-based reward
Very clear and good problem setting using natural language
- In our work we assume an agent only has access to a text description of the goal desired by the user and image observations from the environment. At no point during training or testing does the agent have access to demonstrations, goal images, or reward from the environment. The agent only has access to a reward model that takes images and goal text as input to provide progress towards goal text description with a reward score output. The reward is then used to teach the agent how to achieve the goal described by the text with online reinforcement learning. Given these assumptions we will now describe how we provide a zero-shot reward model by leveraging CLIP and how we learn a text conditioned policy with this model.
Results
Claim
- We argue that existing (e.g., CLIP-like) models can be used to ground the what aspects of a goal quite effectively, including appropriate attribute and concept-level generalization, while a separate where/how module can ground spatial relation- ship aspects of goal configuration.
Summary
CLIP cosine similarity for cur state and goal description