[TOC]
- Title: Pallagani Plansformer Generating Plans 2023
- Author: Pallagani, Vishal et. al.
- Publish Year: GenPlan 2023 Workshop
- Review Date: Tue, Dec 24, 2024
- url: https://arxiw.org/pdf/2212.08681
|
|
[!Note]
please also check MVSplat360 openreview https://openreview.net/forum?id=B0OWOkMwhz&referrer=%5Bthe%20profile%20of%20Bohan%20Zhuang%5D(%2Fprofile%3Fid%3D~Bohan_Zhuang1) in terms of how to do rebuttal.
Also check plangpt openreview https://openreview.net/forum?id=yB8oafJ8bu
Summary of paper

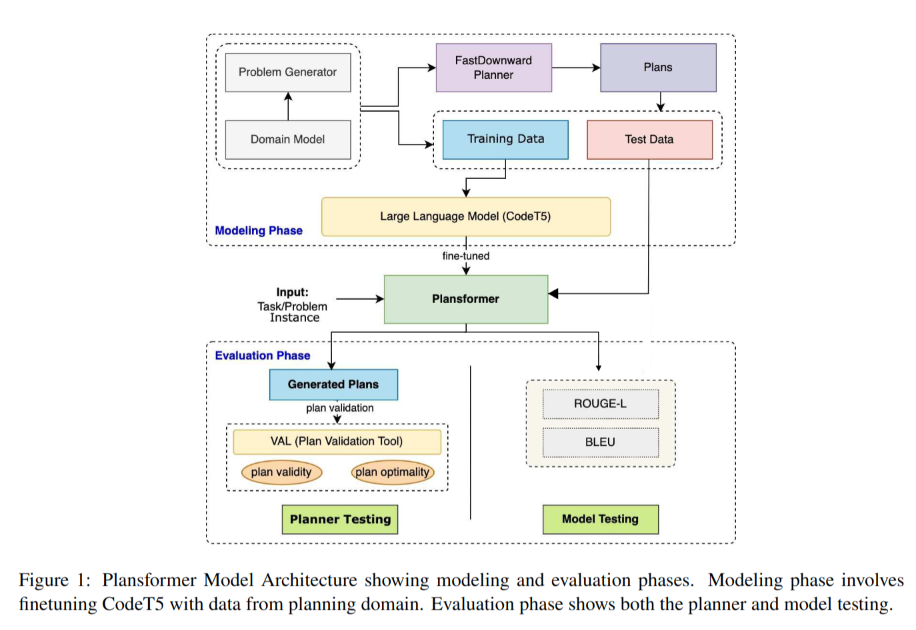
The paper introduces Plansformer, a large language model (LLM) fine-tuned on planning problems to generate symbolic plans. The authors leverage the capabilities of the CodeT5 model, which is pre-trained on code generation tasks, and further fine-tune it on a dataset of planning problems and their corresponding valid plans. The goal is to harness the syntactic and structural knowledge learned by LLMs for natural language tasks and apply it to the domain of automated planning.
The experimental results indicate that the syntactic/symbolic knowledge learned from different programming languages in the CodeT5 model can be beneficial for the PDDL-based automated planning task. For example, in one configuration of Plansformer tested on the Towers of Hanoi domain, the model was able to generate 97% valid plans, out of which 95% are shortest length plans. The results reveal a promising direction to harness LLMs for symbolic tasks such as planning.
The paper evaluates Plansformer using both model testing and planner testing. The model testing uses metrics like ROUGE and BLEU to understand the performance of Plansformer as a language model, while the planner testing uses a plan validation tool to check the validity and optimality of the generated plans. The results show that Plansformer can achieve high plan validity and optimality, reducing the need for extensive knowledge engineering efforts required by traditional planning systems.
Overall, the paper presents a positive attitude towards the use of LLMs for automated planning, demonstrating the potential of Plansformer to generate valid and optimal plans with reduced knowledge engineering efforts compared to traditional planning systems.
Motivation
The motivation of this work is to explore the use of Large Language Models (LLMs) for automated planning
Contribution
- The evaluation of Plansformer’s competence in generating valid and optimal plans, achieving 97% valid plans with 95% optimality on the Towers of Hanoi domain.
Some key terms
- The dataset may be biased, as there is no evidence that LLMs can learn optimal planning by simply maintaining one plan path without knowing how to do heuristic search and pruning. 6
- It is possible that the LLM has already seen similar patterns in the training data and is simply doing pattern matching, rather than reasoning from first principles.
Potential future work
Researchers, particularly from the ICAPS community, have discovered that Large Language Models (LLMs) cannot effectively solve automated planning problems through simple next-token prediction of planning instances. This revelation has led to a critical reassessment of earlier optimistic claims about LLMs’ planning capabilities.
Looking back at the 2022 paper Plansformer, it appears that its claims were overly optimistic. This optimism likely stemmed from flaws in the design of the training and testing datasets.
Further investigation is crucial to unravel the enigma surrounding LLMs’ planning abilities. Some researchers have become overly pessimistic, while others remain too optimistic. Additionally, certain strategies claimed to improve sequential reasoning in LLMs have primarily been tested in mathematical domains, leaving their effectiveness in automated planning contexts uncertain. It is essential to explore whether these strategies can be successfully applied to the automated planning domain, and if they do not directly improve plan validity, we need extra metrics to capture incremental improvements in planning capabilities. By not considering more granular metrics and failing to investigate where strategies fail, researchers miss opportunities to understand how different approaches contribute and which aspects of reasoning need the most attention.