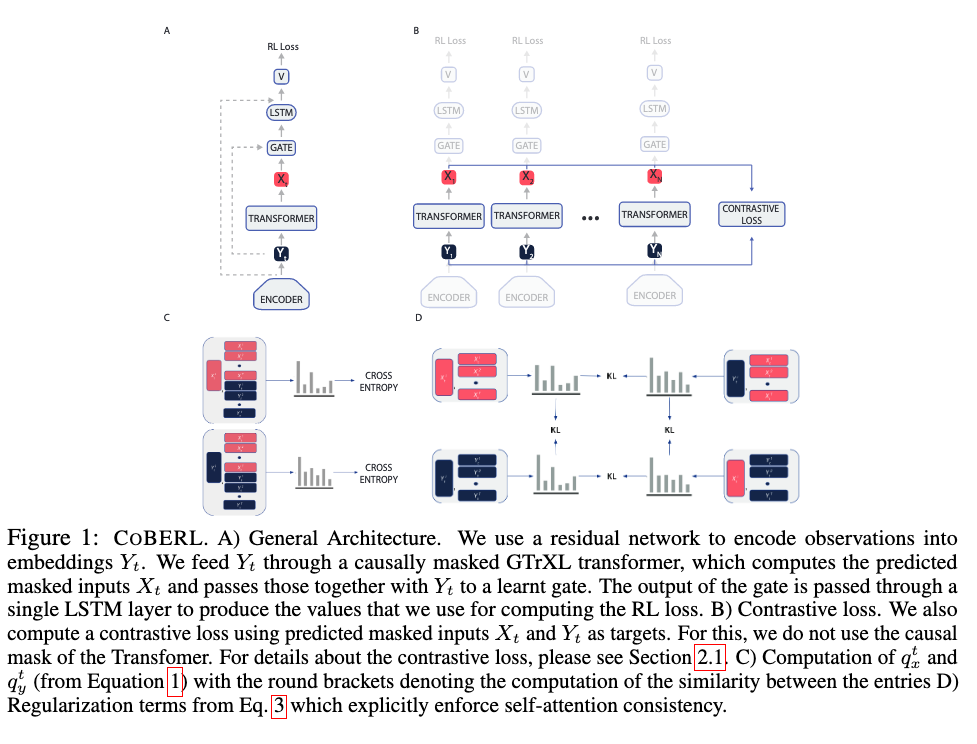
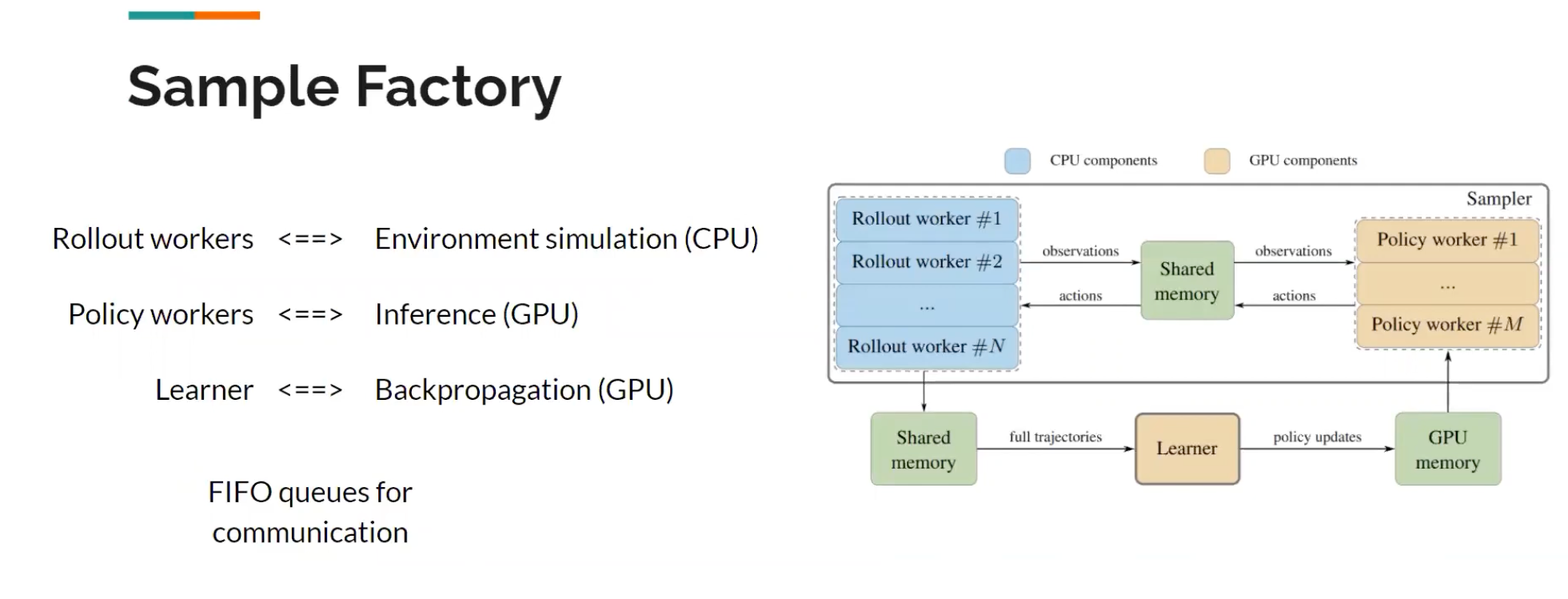
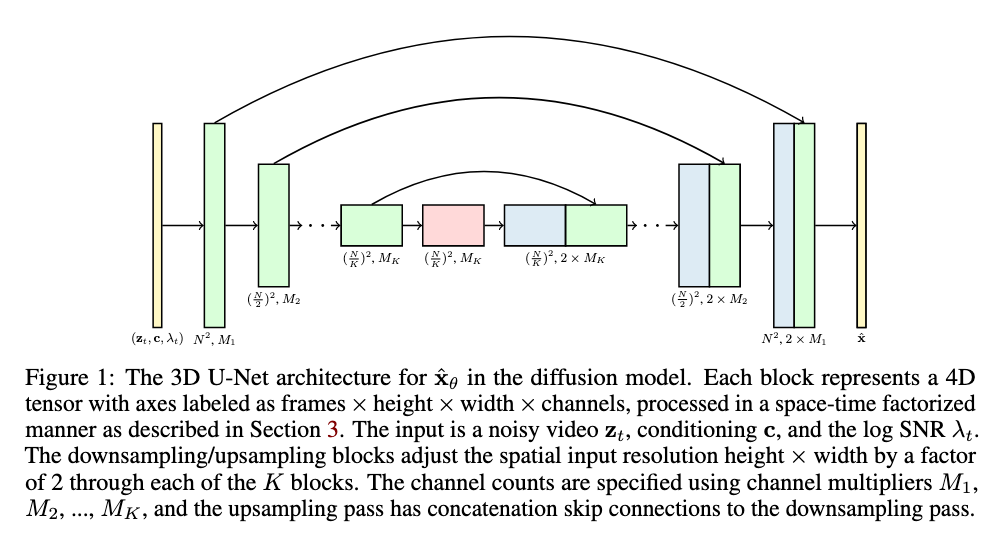
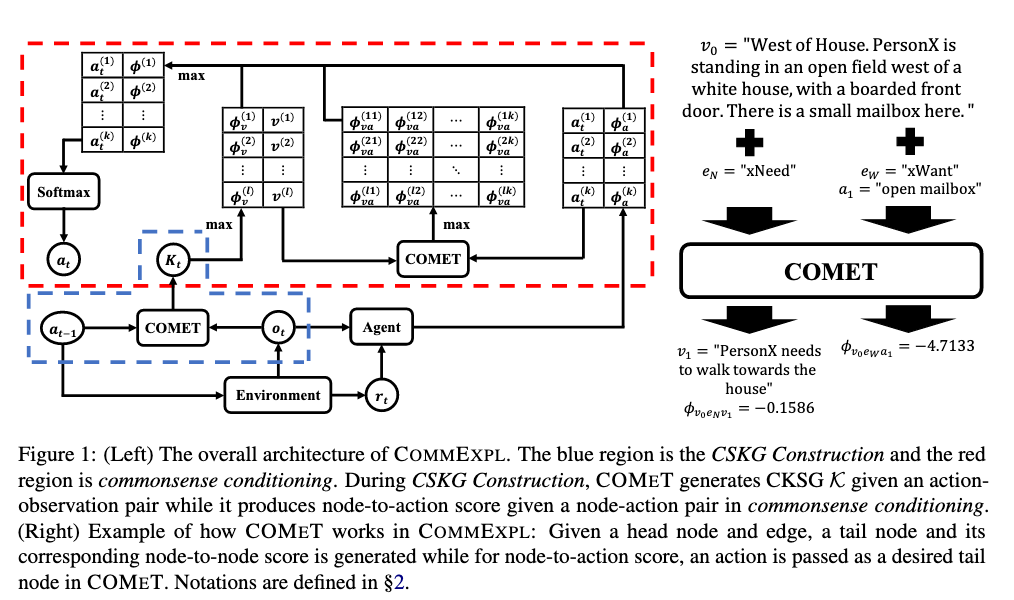
[TOC]
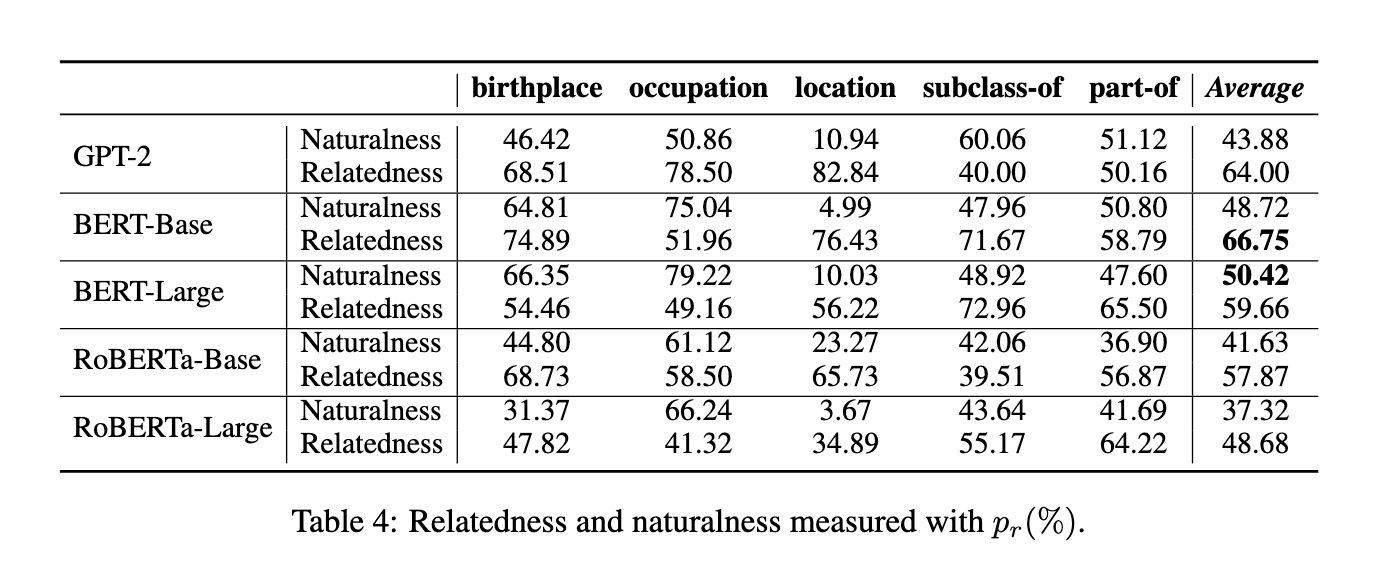
Title: Can Language Models Be Specific? How? Author: Jie Huang et. al. Publish Year: 11 Oct 2022 Review Date: Tue, Nov 8, 2022 Summary of paper Motivation they propose to measure how specific the language of pre-trained language models (PLM) is, To achieve this, they introduced a novel approach to build a benchmark for specificity testing by forming masked token prediction tasks with prompts. for instance given “J.K. Rowling was born in [MASK]”, we want to test whether a more specific answer will be better filled by PLMs. e.g., Yate instead of England it is known that if the prediction is more specific, we can retrieve more fine-grained information from language models, and further acquire more information. viewer’s opinion: we are not saying that summarisation is easy or having less useful information, there are cases that abstract info is more useful Contribution although there are works on measuring how much knowledge is stored in PLMs or improving the correctness of the predictions, non attempted to measure or improve the specificity of prediction made by PLMs. Understanding how specific the language of PLMs is can help us better understand the behaviour of language models and facilitate downstream applications such as question answering etc. setup a dataset benchmark for specificity, The quality of the benchmark is high, where the judgment on which answer is more specific is ∼ 97% consistent with humans. Discovery in general, PLMs prefer less specific answers without subjects given, and they only have a weak ability to differentiate coarse-grained/fine-grained objects by measuring their (cosine) similarities to subjects. the results indicate that specificity was neglected by existing research on language models Improving specificity of the prediction few-shot prompting
...