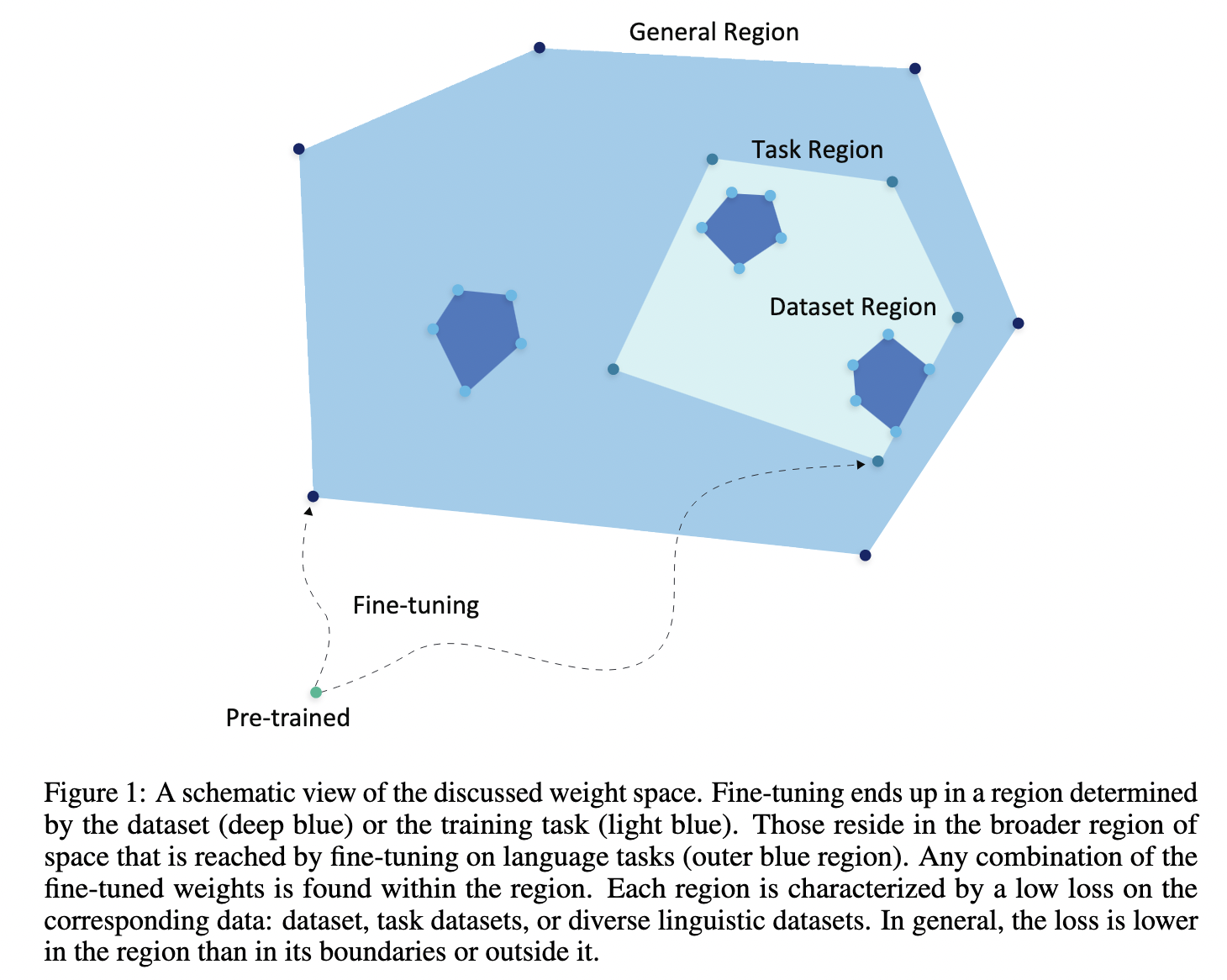
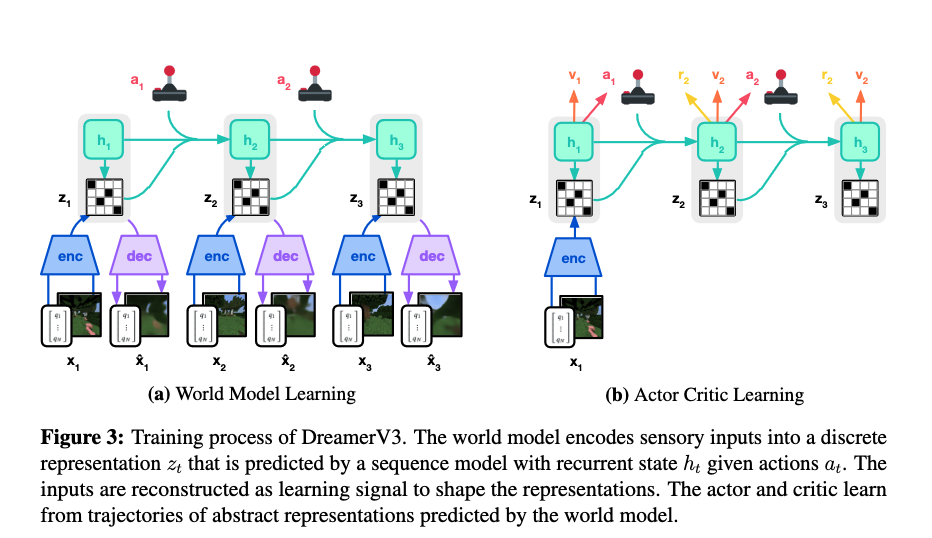
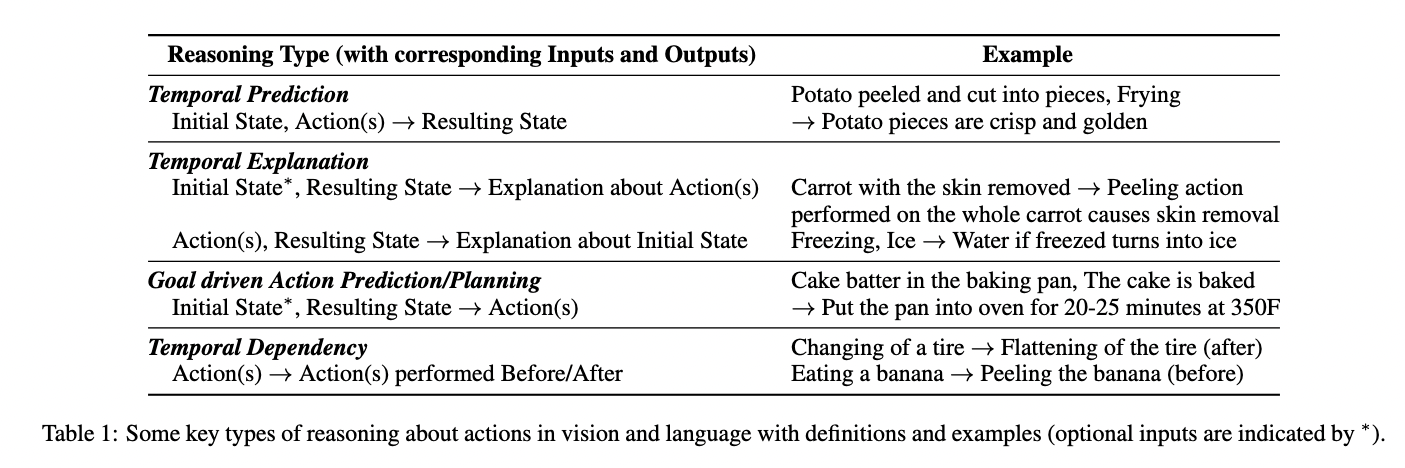
[TOC]
Title: Benchmarks for Automated Commonsense Reasoning a Survey Author: Ernest Davis Publish Year: 9 Feb 2023 Review Date: Thu, Mar 2, 2023 url: https://arxiv.org/pdf/2302.04752.pdf Summary of paper we mainly focus on the section where the author discusses about features of commonsense reasoning generally. Terms clarify what we mean by common sense
what is exactly “commonsensical”? Claims about common sense that seem true to the author Commonsense knowledge is common. In talking to other person, we do not have to explain common sense reasoning or enumerate common sense facts. We can assume that they know that unsupported things fall down, that outside the tropics, days in temperate regions are generally warmer than winter, and so on. Common sense is largely sensible. Any individual person or even an entire society may have various foolish or mistaken beliefs, but for the most part common sense knowledge correponds to the realities of the world as people experience it. Common sense supports reasoning. For example a person who knows that Central Park is in New York and the Golden Gate Bridge is in San Francisco and that New York and San Francisco are 3000 miles apart will realize that they cannot walk from one to the other in fifteen minutes. commonsense reasoning is integrated with other cognitive abilities Common sense extends across tasks and modalities Common sense is a broad scope Commonsense knowledge can be distinguished from common knowledge, encyclopaedic knowledge and expert knowledge Half-truths about commonsense knowledge Commonsense knowledge is language-independent The English-language bias is as pervasive in commmonsense reasoning as in other areas of AI. Impressively, versions of ConceptNet with at least 10,000 concepts exist in 83 different languages, and a few commonsense benchmarks have been translated (table 4) but most resources and benchmarks only exist in English or in a symbolic form in which the symbols are in fact English words or short phrases. Commonsense knowledge is the same for people of different cultures and of different historical periods Even if a belief has been commonsense knowledge for everyone at all times up to the present, that does not mean that that will continue in the future. Commonsense reasoning is fast and intuitive; it falls within “System 1” Processes in System 1 characteristically are executed quickly, do not require conscious thought, are not open to introspection, in at least in some cases are not controllable (one cannot decide not to interpret what one is seeing), and do not place a cognitive burden on working memory; vision is a paradigmatic example. Processes in System 2 are the reverse: slow, consciously carried out, consciously controllable, instrospectable, and taxing on working memory. System 2 processes can call on system 1 but not vice versa, since a fast process cannot use a slow subroutine. encyclopaedic and expert knowledge can also be called on in System 1 activities Commonsense knowledge can be expressed using simple language it seems plausible: basic vocabulary tends to refer to the well-known concepts and relations which are the subject of commonsense knowledge however, there is a very large exception here, which is commonsense spatial knowledge. Natural language is notoriously ill-suited to the description of characteristics of shapes and positions that are easily apprehended (bad expressivity of natural language) An untrue claim about commonsense knowledge commonsense knowledge is not logically complex However, in physical reasoning, understanding the physical characteristics could be quite complex (e.g., considering angry birds). But humans are good at playing angry birds.