
[TOC]
- Title: Reinforcement Learning With Constrained Uncertain Reward Function Through Particle Filtering
- Author: Oguzhan Dogru et. al.
- Publish Year: July 2022
- Review Date: Sat, Dec 24, 2022
Summary of paper
Motivation
- this study consider a type of uncertainty, which is caused by the sensor that are utilised for reward function. When the noise is Gaussian and the system is linear
Contribution
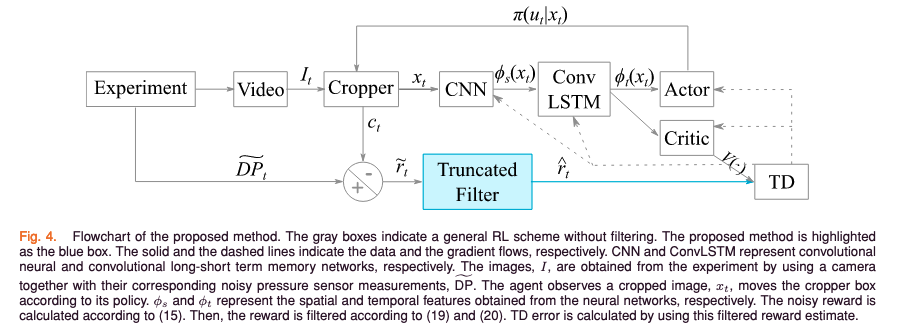
- this work used “particle filtering” technique to estimate the true reward function from the perturbed discrete reward sampling points.
Some key terms
Good things about the paper (one paragraph)
Major comments
Citation
- complex control problems today are often solved by black-box methods that are data driven. this is because the SOTA techniques have made it possible to process high-dimensional data in real time. Despite the practicality of these techniques, this data-driven era has its challenges: data reliability.
- ref: Dogru, Oguzhan, Ranjith Chiplunkar, and Biao Huang. “Reinforcement learning with constrained uncertain reward function through particle filtering.” IEEE Transactions on Industrial Electronics 69.7 (2021): 7491-7499.
- learning may be considered solving an optimisation problem with an associated reward function.
- ref: Dogru, Oguzhan, Ranjith Chiplunkar, and Biao Huang. “Reinforcement learning with constrained uncertain reward function through particle filtering.” IEEE Transactions on Industrial Electronics 69.7 (2021): 7491-7499.
- Although uncertainty in the reward has been reported to degrade model/controller performance, no empirical analysis has been conducted on the RL algorithm’s tolerance for reward perturbations.
- ref: J. Wang, Y. Liu, and B. Li, “Reinforcement learning with perturbed rewards,” in Proc. AAAI Conf. Artif. Intell., 2020, vol. 34, pp. 6202–6209
limitation of the experiment setting
- This particle filtering technique is not applicable for the sparse reward signal setting. Moreover, the noise filtering technique requires further rounds of simulation steps to generate estimate of the real reward, which makes the RL training further sample inefficient.