[TOC]
- Title: Policy Optimization in Noisy Neighborhood
- Author: Nate Rahn et. al.
- Publish Year: NeruIPS 2023
- Review Date: Fri, May 10, 2024
- url: https://arxiv.org/abs/2309.14597
Summary of paper

Contribution
- in this paper, we demonstrate that high-frequency discontinuities in the mapping from policy parameters $\theta$ to return $R(\theta)$ are an important cause of return variation.
- As a consequence of these discontinuities, a single gradient step or perturbation to the policy parameters often causes important changes in the return, even in settings where both the policy and the dynamics are deterministic.
- unstable learning in some sense
- based on this observation, we demonstrate the usefulness of studying the landscape through the distribution of returns obtained from small perturbation of $\theta$
Some key terms
Evidence that noisy reward signal leads to substantial variance in performance
It is well-documented that agents trained with deep reinforcement learning can exhibit substantial variations in performance – as measured by their episodic return. The problem is particularly acute in continuous control, where these variations make it difficult to compare the end product of different algorithms or implementations of the same algorithm [ 11 , 20 ] or even reliably measure an agent’s progress from episode to episode [9].
[9] Stephanie CY Chan, Samuel Fishman, Anoop Korattikara, John Canny, and Sergio Guadarrama. Measuring the Reliability of Reinforcement Learning Algorithms. In International Conference on Learning Representations, 2019.
[11] Cédric Colas, Olivier Sigaud, and Pierre-Yves Oudeyer. A hitchhiker’s guide to statistical comparisons of reinforcement learning algorithms. In Reproducibility in Machine Learning, ICLR 2019 Workshop, New Orleans, Louisiana, United States, May 6, 2019. OpenReview.net, 2019.
[12] Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. In International conference on machine learning, pages 1309–1318. PMLR, 2018
Results
Observation on the performance
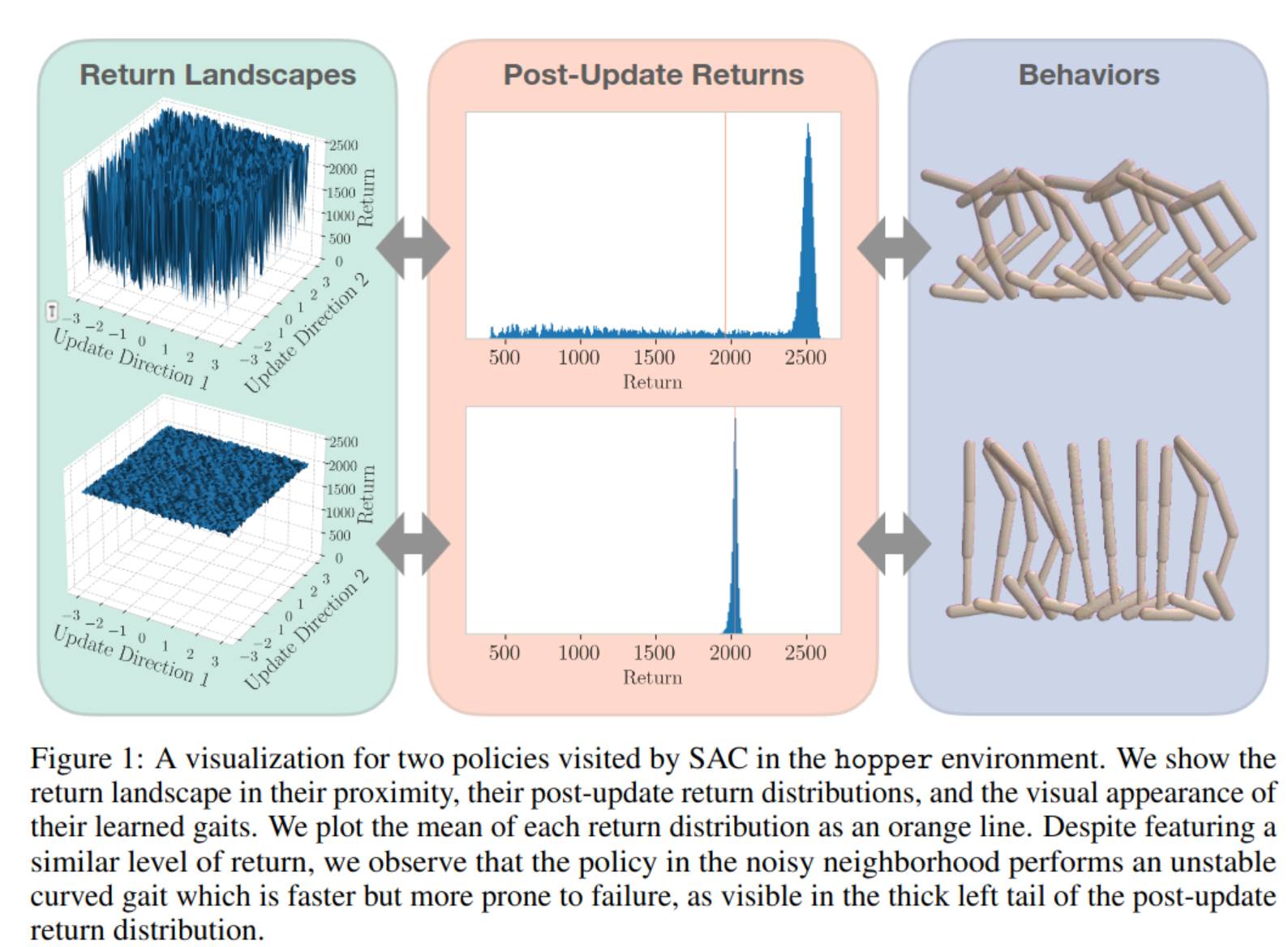
- We find qualitatively that the policy in the noisy neighborhood exhibits a curved gait which is sometimes faster, but unstable, whereas the policy in the smooth neighborhood produces an upright gait which can be slower, yet is very stable
Unstability
- Taken together, these results demonstrate that some policies exist on the edge of failure, where a slight update can trigger the policy to take actions which push it out of its stable gait and into catastrophe
interpolation policy in the same run
-
Definition of same run: starting from the same initialization and history of batches, that is one $\theta$ is the old intermediate version of the latest $\theta$
-
By contrast, when interpolating between policies from the same run, the transition from a noisy to a smooth landscape happens without encountering any valley of low return – even when these policies are separated by hundreds of thousands of gradient steps in training. This is particularly surprising given that θ is a high-dimensional vector containing all of the weights of the neural network, and there is no a priori reason to believe that interpolated parameters should result in policies that are at all sensible.
Summary
This work focus on how to stabilize the policy training.
Sadly it did not consider the case where the reward signal is noisy