
[TOC]
- Title: Evaluating Large Language Models Trained on Code
- Author: Mark Chen et. al. OPENAI
- Publish Year: 14 Jul 2021
- Review Date: Mon, Oct 16, 2023
- url: https://arxiv.org/pdf/2107.03374.pdf
Summary of paper
Motivation
- it is the research paper behind Github Copilot tech
- more recently, language models have also fueled progress towards the longstanding challenge of program synthesis.
Contribution
- we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts.
limitation
- difficulty with docstrings describing long chain of operations and with binding operations to variables.
Some key terms
HumanEval
- a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings.
preliminary test
- our early investigation of GPT-3 revealed that it could generate simple program from Python docstring.
- thus we hypothesise that a specialised GPT model, could excel at a variety of coding tasks.
evaluation framework
- generative models for code are predominantly benchmarked by matching samples against reference solution, where the match can be exact or fuzzy (as in BLEU score)
- however, Ren et. al. (2020) finds that BLEU has problem capturing semantic features specific to code, and suggests several semantic modification to the score.
- More fundamentally, match-based metrics are unable to account for the large and complex space of programs functionally equivalent to a reference solution.
functional correctness
-
this is a more suitable evaluation metric compared to match-based one
-
where a sample is considered correct if it passes a set of unit tests
Methods
observation
- they found that surprisingly, they did not observe improvements when starting from a pre-trained language model, possible because the fine-tuning dataset is so large. Nevertheless, models fine-tuned from GPT converge more quickly.
supervised fine-tuning

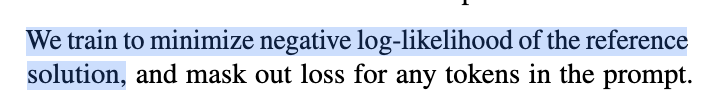
multiple samples generation and ranking
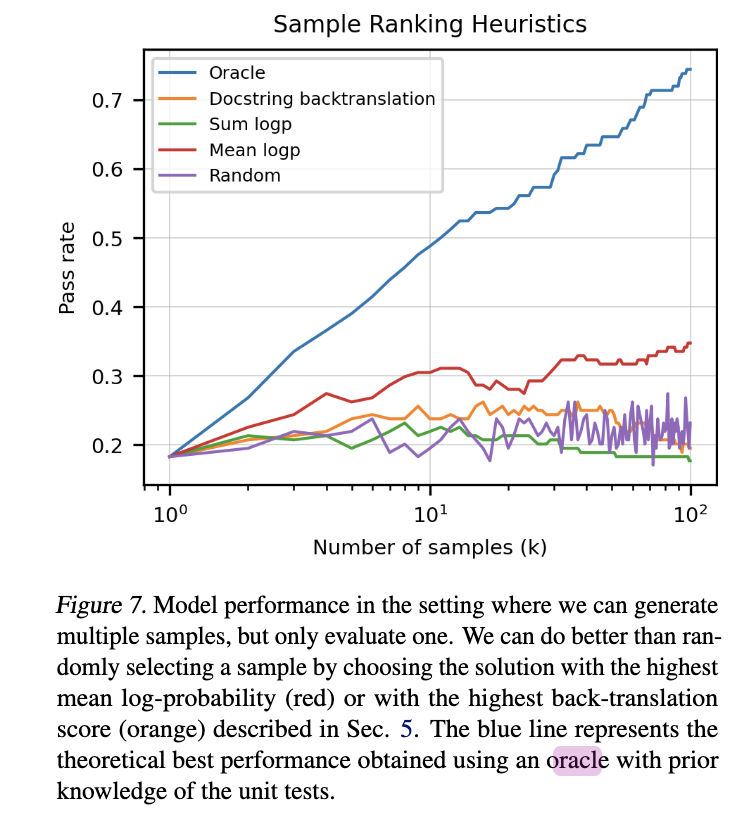
**back-translation to pick the sample **


- issue: this heuristic appears to overfit quickly.