[TOC]
- Title: Learning Generative Models With Goal Conditioned Reinforcement Learning
- Author: Mariana Vargas Vieyra et. al.
- Publish Year: 26 Mar 2023
- Review Date: Thu, Mar 30, 2023
- url: https://arxiv.org/abs/2303.14811
Summary of paper

Contribution
- we present a novel framework for learning generative models with goal-conditioned reinforcement learning
- we define two agents, a goal conditioned agent (GC-agent) and a supervised agent (S-agent)
- Given a user-input initial state, the GC-agent learns to reconstruct the training set. In this context, elements in the training set are the goals.
- during training, the S-agent learns to imitate the GC-agent while remaining agnostic of the goals
- At inference we generate new samples with S-agent.
Some key terms
Goal-Conditioned Reinforcement Learning (GCRL) framework
- in GCRL the agent aims at a particular state called the goal.
- at each step, the environment yields a loss that accounts how far the agent is from the goal it is targeting (potential based reward shaping)
- intuitively, our learning procedure consists of training a family of goal-conditioned agent (GC-policy) that learn to reach the different elements in the training set by producing a trajectory of intermediate representations, departing from the fixed initial state (the alternative view for reverse diffusion process)
- at the same time, we obtain the generative model by learning a mixture policy of these goal-conditioned policies where the goal is sampled uniformly at random from the training set.
- the goal-conditioned agents are used for training only. At inference time, we generate trajectories with the mixture policy and collect the states reached at the final step.
Algorithm
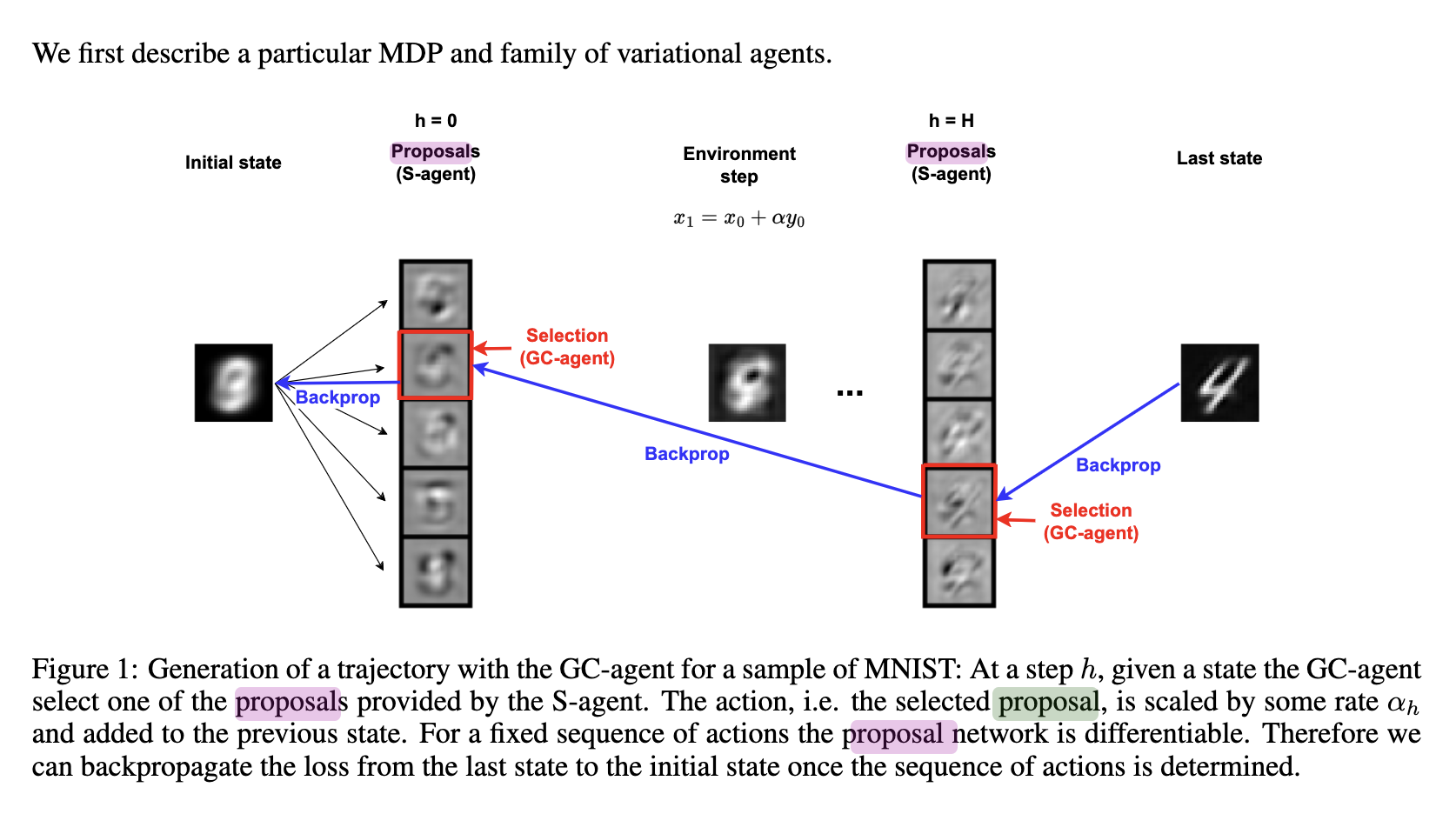
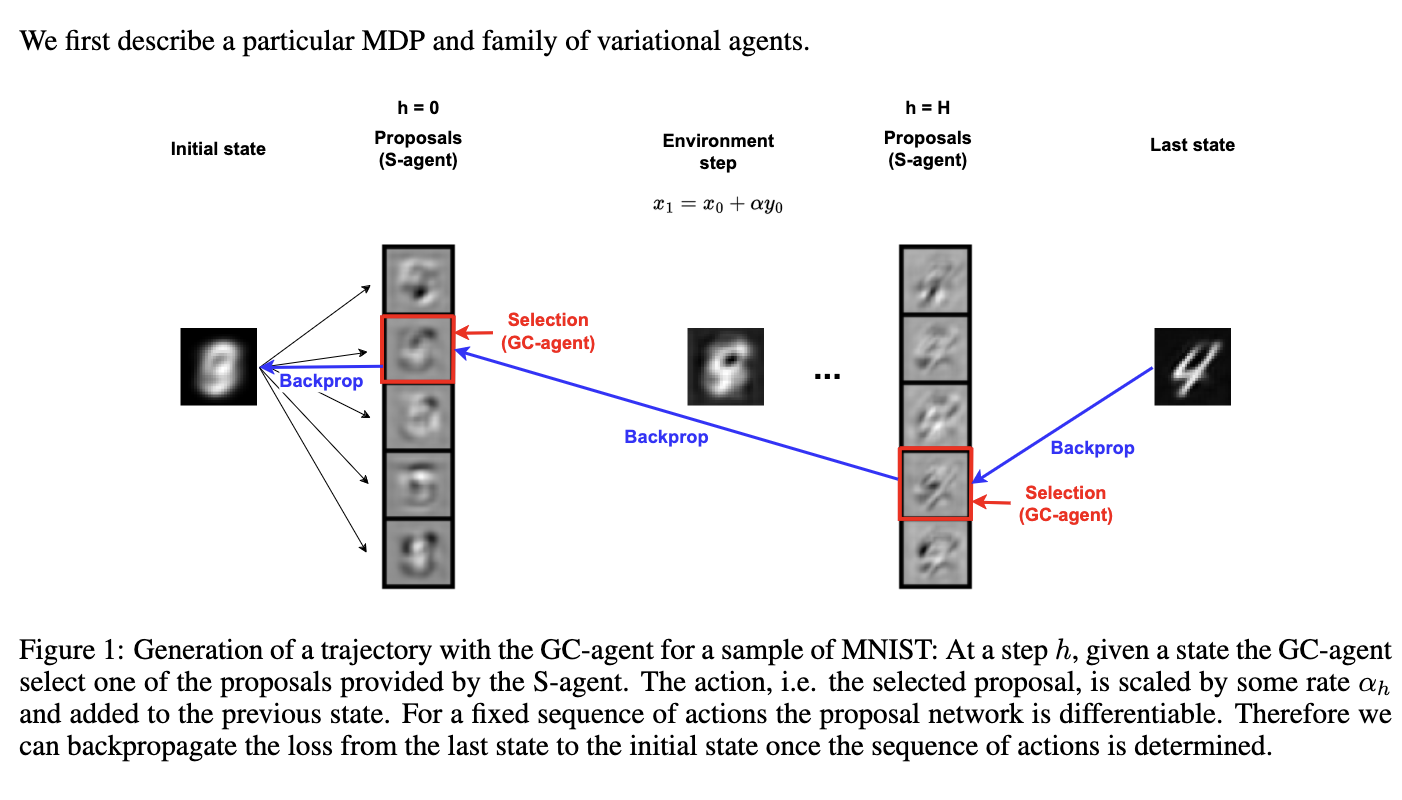
- S-agent generates proposal
- GC-agent selects proposal as action selection
what is proposal
- is the action vector
- But in this setting, the agent need to select the best proposal among $A$ proposals and set $A$ changes for each step.
- Therefore, we traded a GCRL task with continuous action space for a non-stationary GCRL task with discrete action space.
Potential future work
The paper redefined the diffusion model as a goal-conditioned RL problem