[TOC]
- Title: Can Wikipedia Help Offline Reinforcement Learning
- Author: Machel Reid et. al.
- Publish Year: Mar 2022
- Review Date: Mar 2022
Summary of paper
Motivation
Fine-tuning reinforcement learning (RL) models has been challenging because of a lack of large scale off-the-shelf datasets as well as high variance in transferability among different environments.
Moreover, when the model is trained from scratch, it suffers from slow convergence speeds
In this paper, they look to take advantage of this formulation of reinforcement learning as sequence modelling and investigate the transferability of pre-trained sequence models on other domains (vision, language) when fine tuned on offline RL tasks (control, games).
How do they do
encouraging similarity between language representations and offline RL input representations
they add one term in the objective named L_cos

this objective wants that each input representation should at least be corresponded to one word. (this is wired…)
but they said that they tested mean pooling and they found out that the model cannot converge.
I is the input (either reward, action or state), E is the word embedding

Some key terms
the zero-shot performance of transformer based language models

offline RL and sequence modelling
offline reinforcement learning (RL) has been seen as analogous to sequence modelling, framed as simply supervised learning to fit return-augmented trajectories in an offline dataset.
offline RL model


this paper wants to adapt pre-trained language model (from Wikipedia) to offline RL (in continuous control and games)
offline reinforcement learning

in offline RL, the objective remains the same, but has to be optimised with no interactive data collection on a fixed set of trajectory $\tau_i$ $$ \tau = (r_1,s_1,a_1,r_2,s_2,a_2,…,r_N,s_N,a_N) $$
Good things about the paper (one paragraph)
Major comments
Minor comments
decision transformer
In the Abstract it said “recent work has looked at tackling offline RL from the perspective of sequence modelling with improved results as result of the introduction of the Transformer architecture”
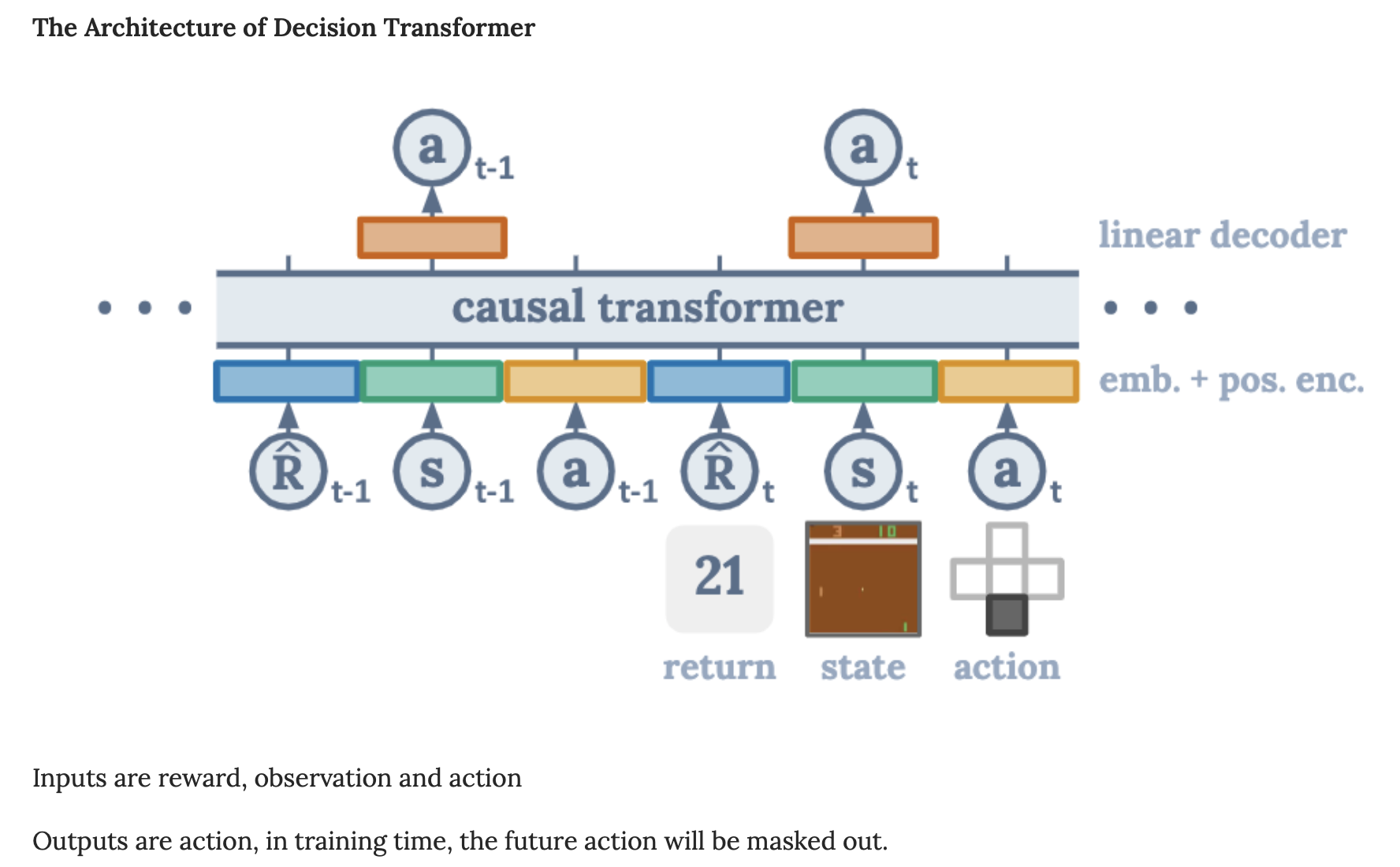
Incomprehension
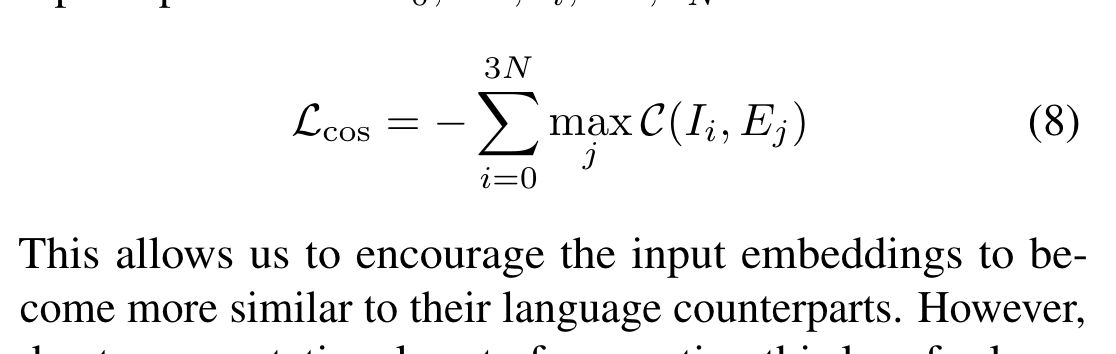
I don’t why this is a good way to encourage similarity between language representations and offline RL input representations.
Potential future work
Is there a better way to encourage RL input embedding and word embeddings stay in the same latent space?