[TOC]
- Title: Scaling Expert Language Models With Unsupervised Domain Discovery
- Author: Luke Zettlemoyer et. al.
- Publish Year: 24 Mar, 2023
- Review Date: Mon, Apr 3, 2023
- url: https://arxiv.org/pdf/2303.14177.pdf
Summary of paper

Contribution
- we introduce a simple but efficient method to asynchronously train large, sparse language models on arbitrary text corpora.
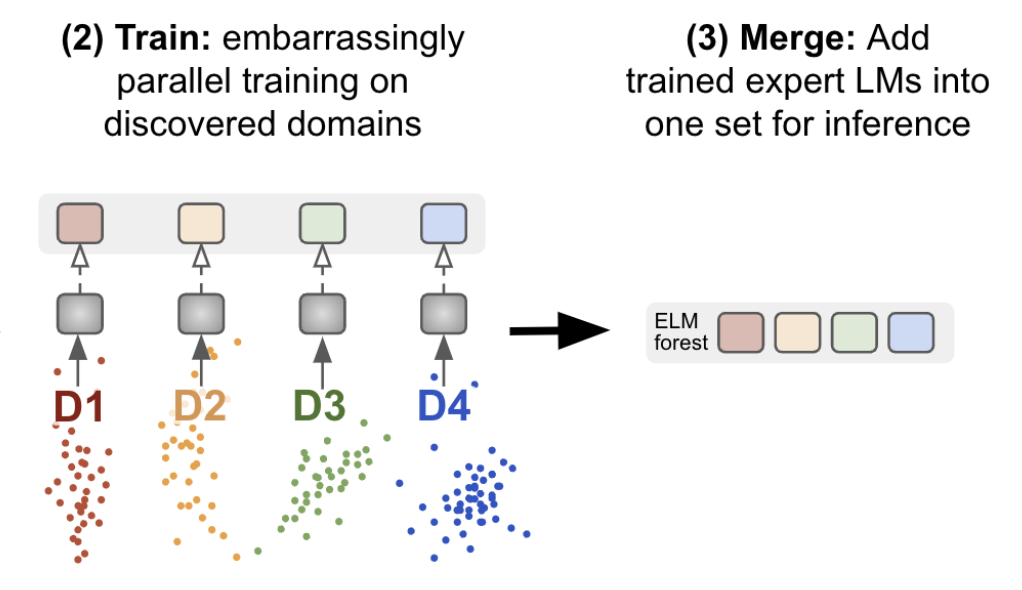
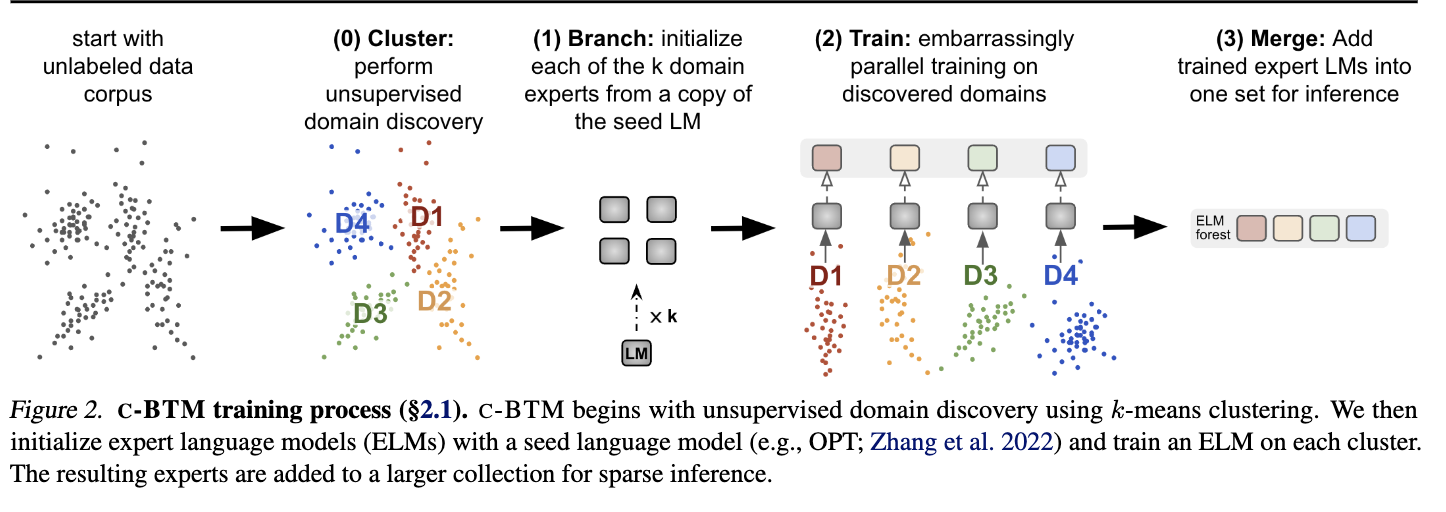
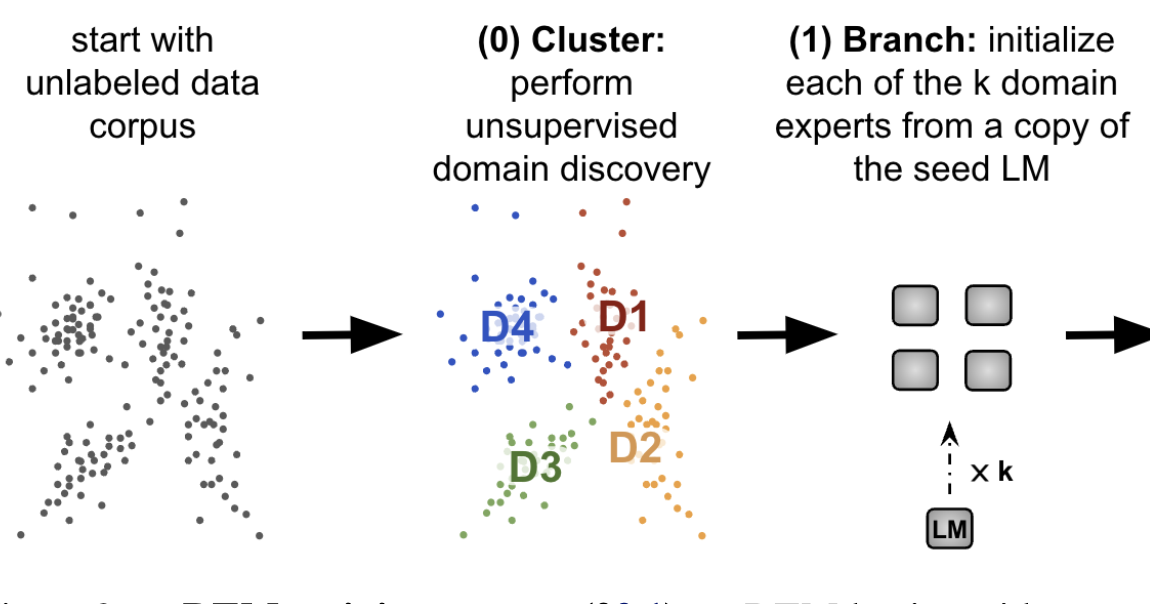
- Our method clusters a corpus into sets of related documents, trains a separate expert language model on each cluster, and combines them in a sparse ensemble for inference.
- This approach generalise embarrassingly parallel training by automatically discovering the domain for each expert, and eliminates nearly all the communication overhead of existing sparse language models.
Some key terms
Cluster-Branch-Train-Merge (C-BTM)
-
We use unsupervised clustering to discover domains in a corpus, and train an ELM on each cluster independently.
-
At inference time, we sparsely activate a subset of the trained ELMs. We ensemble ELMs by weighting their output with the distances between an embedding of the current context and each expert’s cluster center.
-
-