[TOC]
- Title: Decision Transformer: Reinforcement Learning via Sequence Modeling
- Author: Lili Chen et. al.
- Publish Year: Jun 2021
- Review Date: Dec 2021
Summary of paper
The Architecture of Decision Transformer
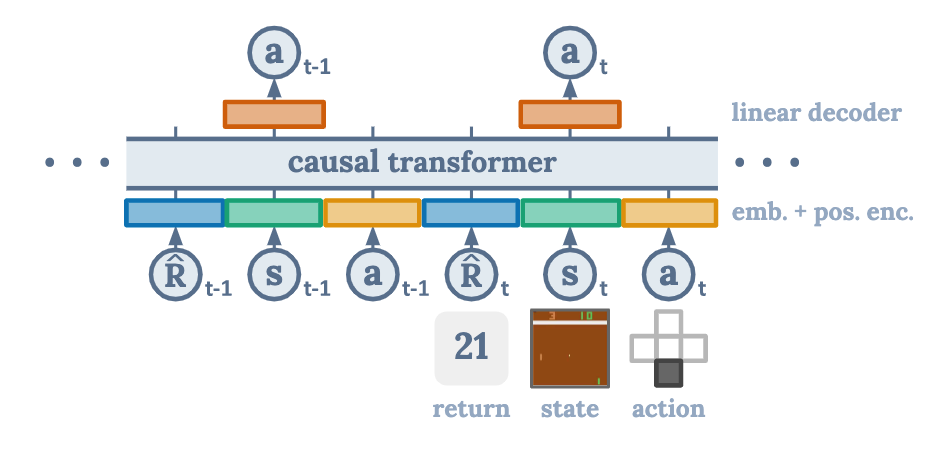
Inputs are reward, observation and action
Outputs are action, in training time, the future action will be masked out.
I believe this model is able to generate a very good long sequence of actions due to transformer architecture.
But somehow this is not RL anymore because the transformer is not trained by reward signal …
What is the difference between decision transformer and normal RL
there is no more value expectation and argmax over action.
instead, they will provide the model with the reward value we want, and then the transformer output an action that try to obtain the reward as close as the proposed reward $\hat R$
(so no more arg max action, but rather $a \in A, R(a,s) \approx \hat R$)
(NOTE: this is related to upside down RL)
NOTE: can we extend this to goal condition RL ?
off policy RL and training dataset matches transformer architecture
this is the illustration
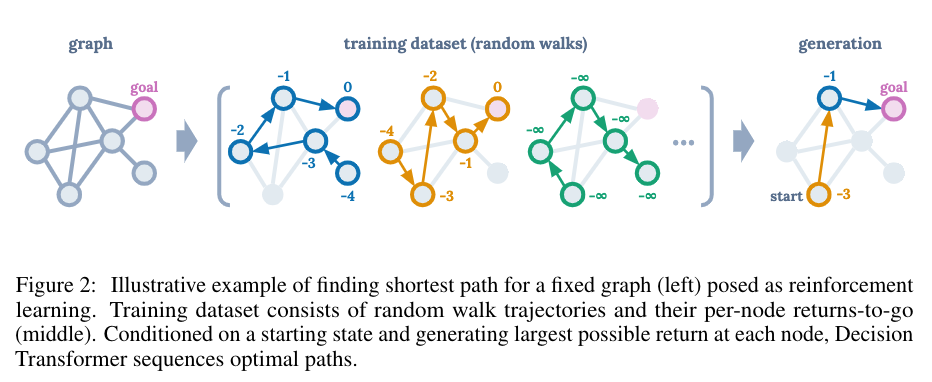
The full algorithm

Some key terms
recall dynamic programming
in addition to action output, the model should also output the value of the state to estimate the final reward of your strategy.
Later we learn the model using temporal difference learning (TD)
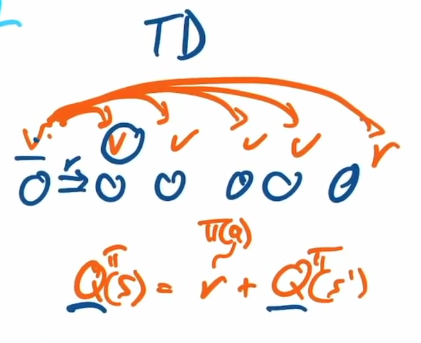
Q learning is on the concept of dynamic programming
What is Key-To-Door game
the author claimed that their transformer model is able to solve tasks with long dependency (i.e., the current action may have big influence in the future state and future reward gain)
This is the similar situation when RL is difficult to solve games that require intensive exploration
Possible Issue
The training dataset may be very significant because the training dataset will eventually model the behaviour of the agent.
The issue would be “how to really let the agent explore by itself”
how to combine the traditional RL to this kind of sequence modelling
- sequence modelling is highly dependent on the training dataset
- RL is data inefficient, but it can gradually perform good actions.
Potential future work
Maybe a sequence modelling is quite good to solve IGLU competition because the setting in IGLU is Markov.
(i.e., the action you perform is only dependent on the current state and there should not be very long dependency)