[TOC]
- Title: MPNet: Masked and Permuted Pre-training for Language Understanding
- Author: Kaitao Song et. al.
- Publish Year: 2020
- Review Date: Thu, Aug 25, 2022
Summary of paper
Motivation
-
BERT adopts masked language modelling (MLM) for pre-training and is one of the most successful pre-training models.
-
Since BERT is all attention block and the positional embedding is the only info that care about the ordering, BERT neglects dependency among predicted tokens
- XLNet introduces permuted language modelling (PLM) to address dependency among the predicted tokens.
- So in addition to XLNet, MPNet takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy
Contribution
- Obtain better results than BERT and XLNet
Some key terms
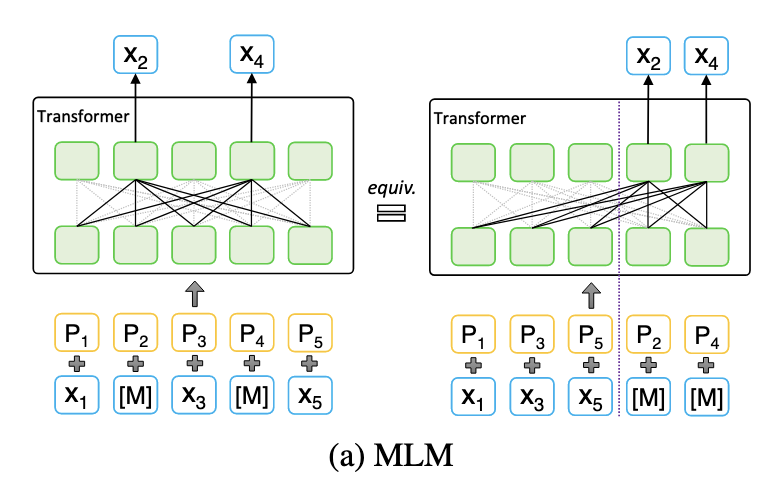
Comparison between BERT and XLNet
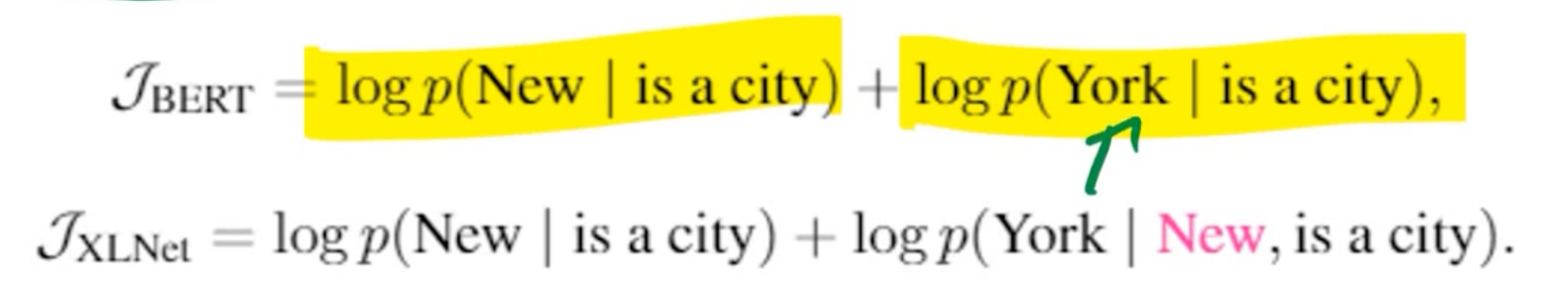
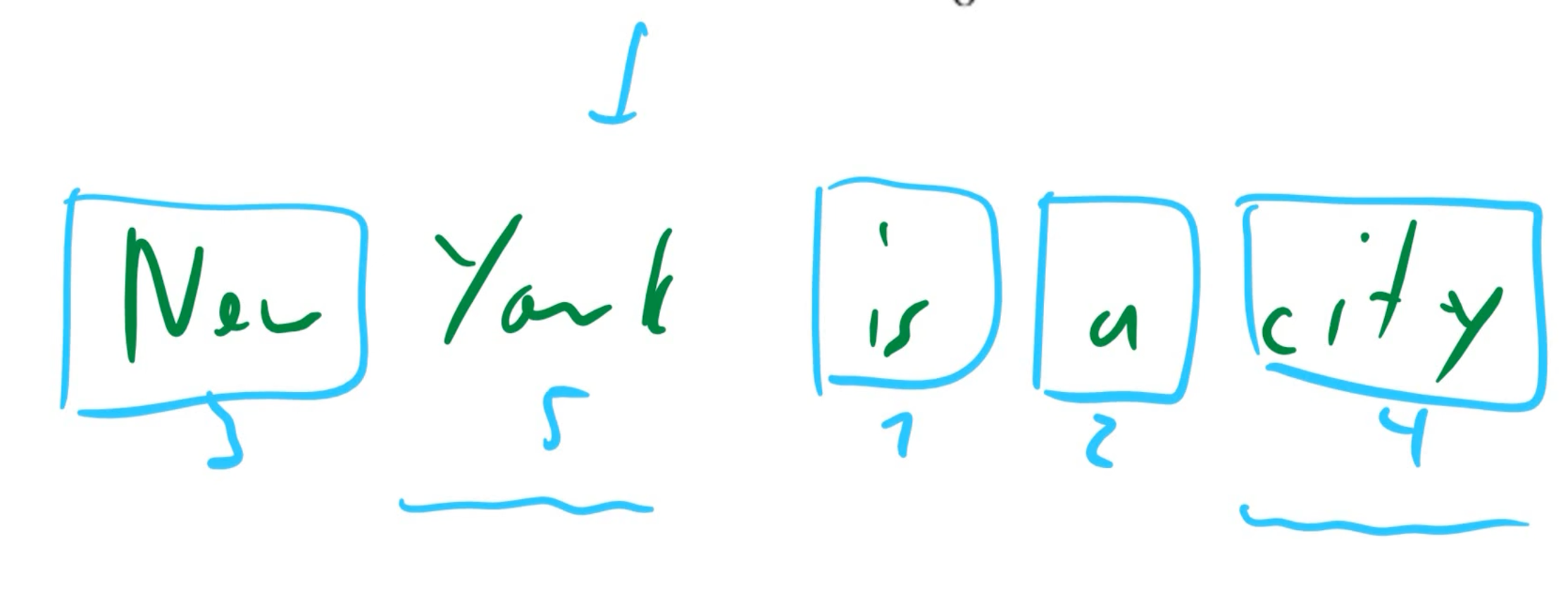
Limitation (Output dependency) in Autoencoding (BERT)
MLM assumes the masked token are independent with each other and predicts them separately, which is not sufficient to model the complicated context dependency in natural language
- e.g., [MASK] [MASK] is a city -> New York is a city (MLM autoencoding)
- the dependency between New and York are not captured
In contrast, PLM factorizes the predicted tokens with the product rule in any permuted order, which avoids the independence assumption in MLM and can better model dependency among predicted tokens.
Limitation (position discrepancy) in random shuffling autoregression (XLNet)
Since in downstream tasks, a model can see the full input sentence to ensure the consistency between the pre-training and fine-tuning, the model should see as much as information as possible of the full sentence during pre-training. In MLM, their position information are available to the model to (partially) represent the information of full sentence (how many tokens in a sentence i.e., the sentence length).
- However, each predicted tokens in PLM can only see its preceding tokens in a permuted sentence but does not know the position information of the full sentence during the autoregressive pretraining, which brings discrepancy between pre-training and fine-tuning.
- so as long as the downstream task is not text generation, then autoregression method has this limitation.
Proposed method
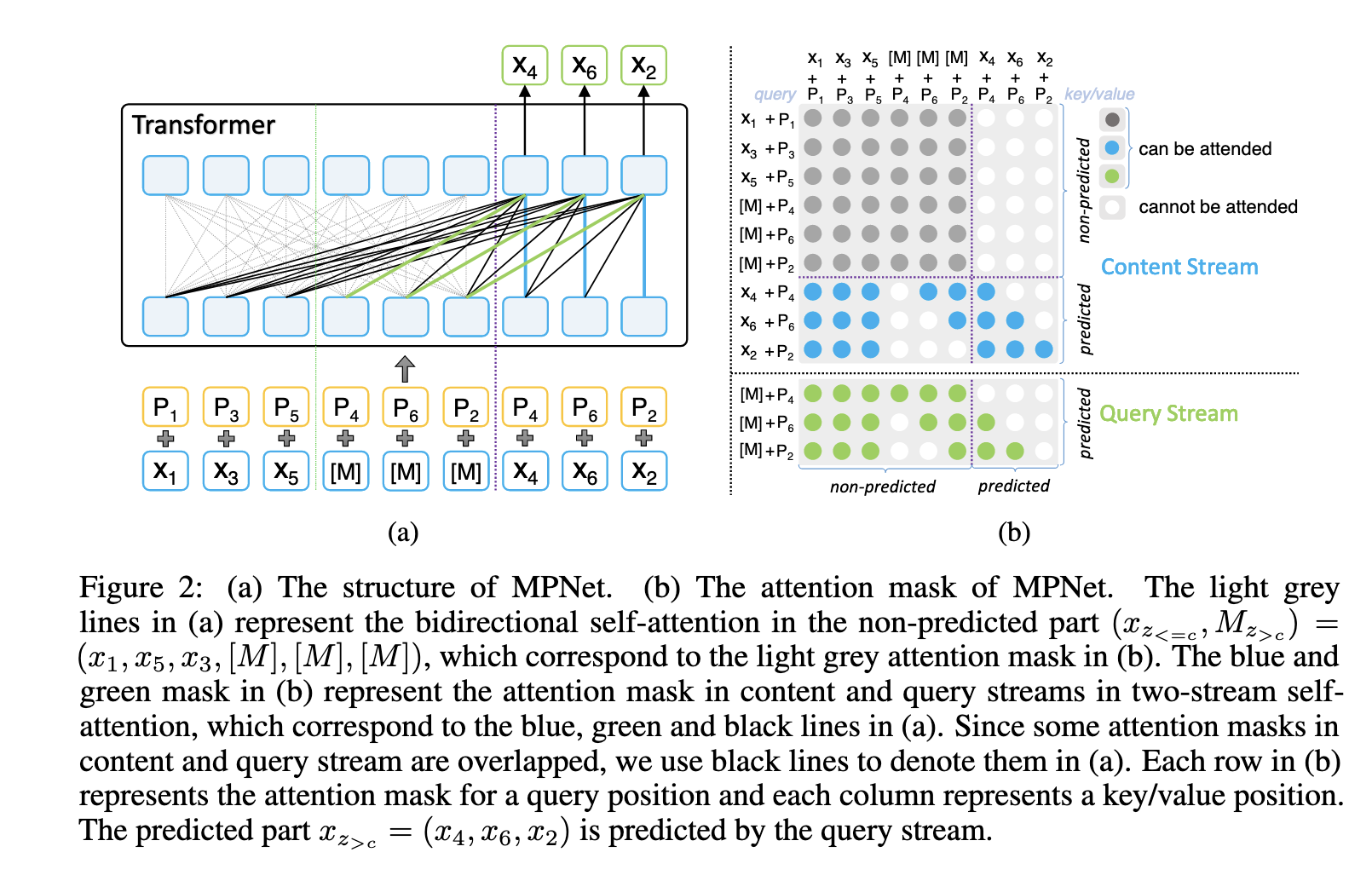
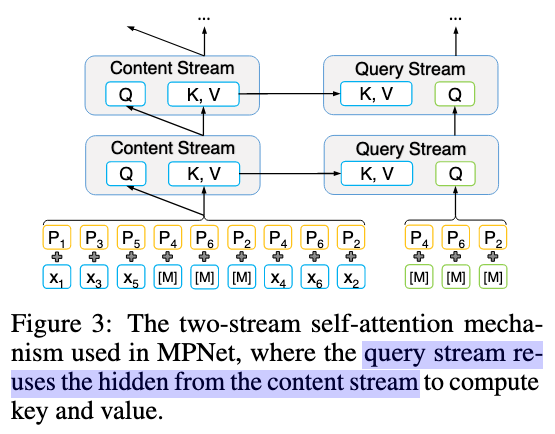
Architecture
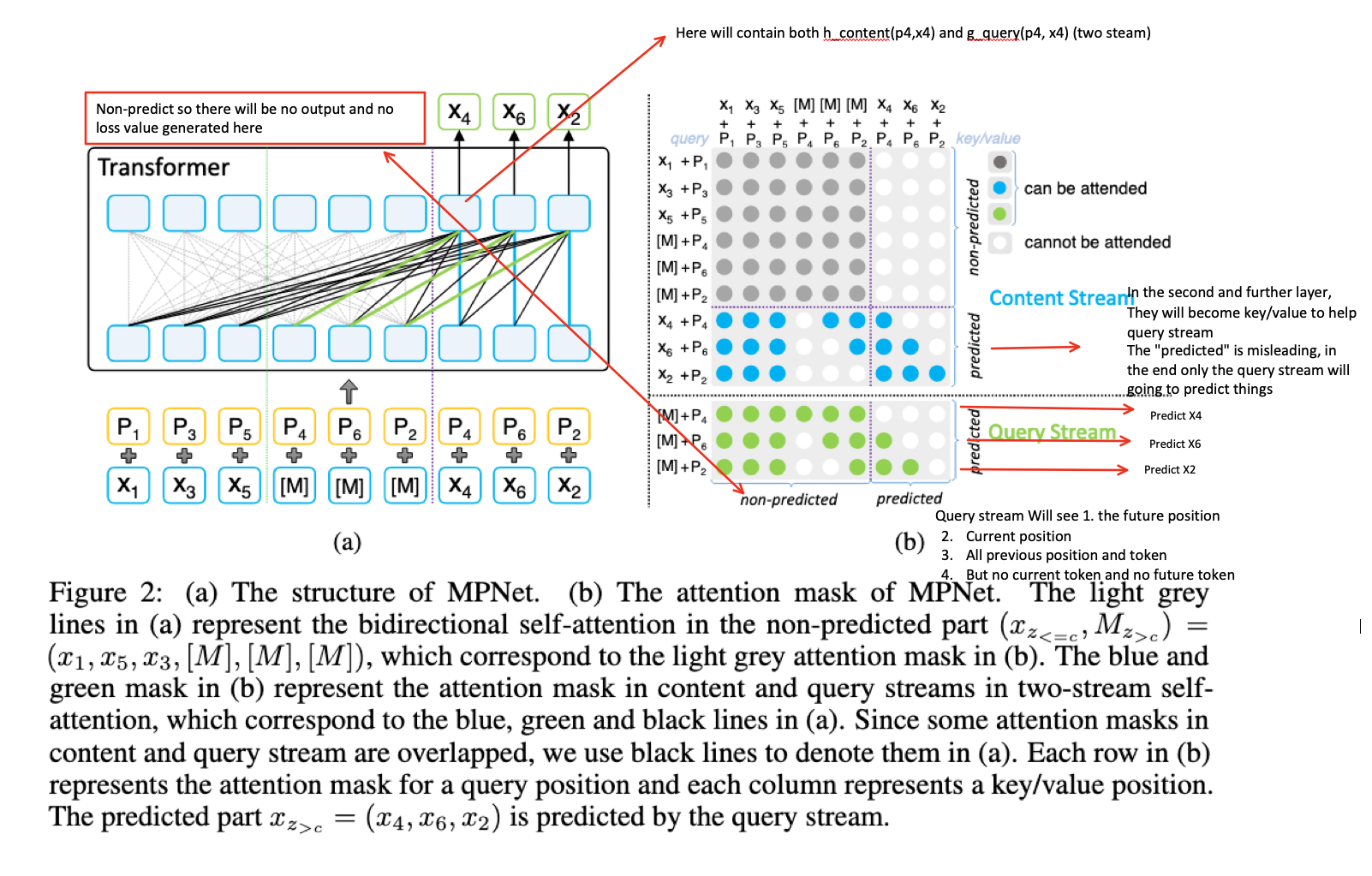
Two-stream diagram (not clear actually)

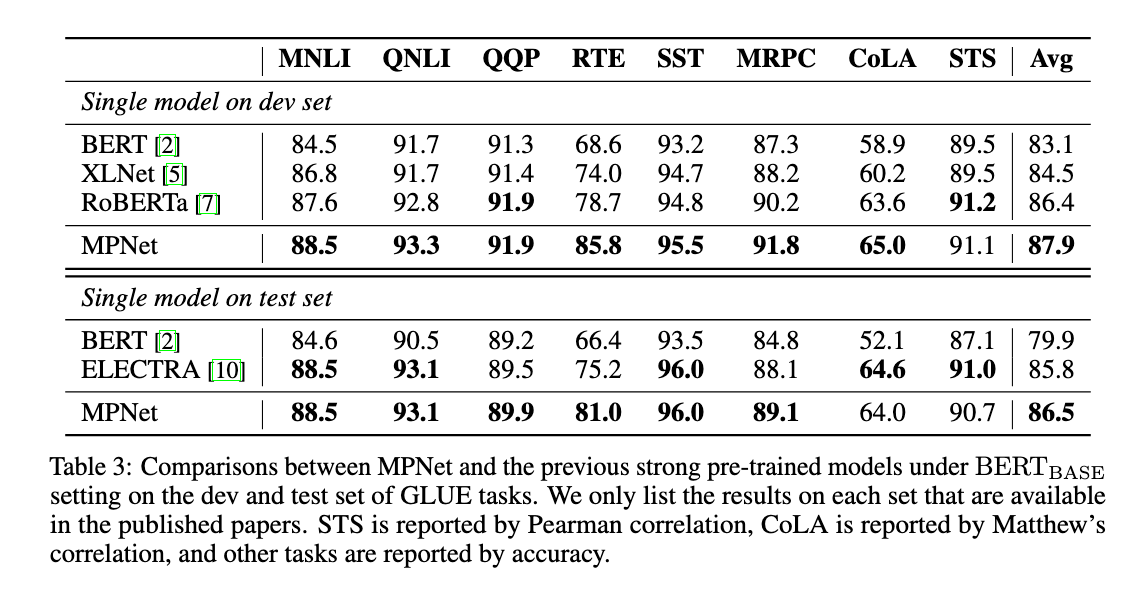
Results
Good things about the paper (one paragraph)
quite good and combine all the stuffs together
Potential future work
We may use this model to get temporal information for video input