[TOC]
- Title: M6: A Chinese Multimodal Pretrainer
- Author: Junyang Lin et. al.
- Publish Year: May 2021
- Review Date: Jan 2022
Summary of paper
This paper re-emphasises that
- large model trained on big data have extremely large capacity and it can outperform the SOTA in downstream tasks especially in the zero-shot setting.
So, the author trained a big multi-modal model
Also, they proposed a innovative way to tackle downstream tasks.
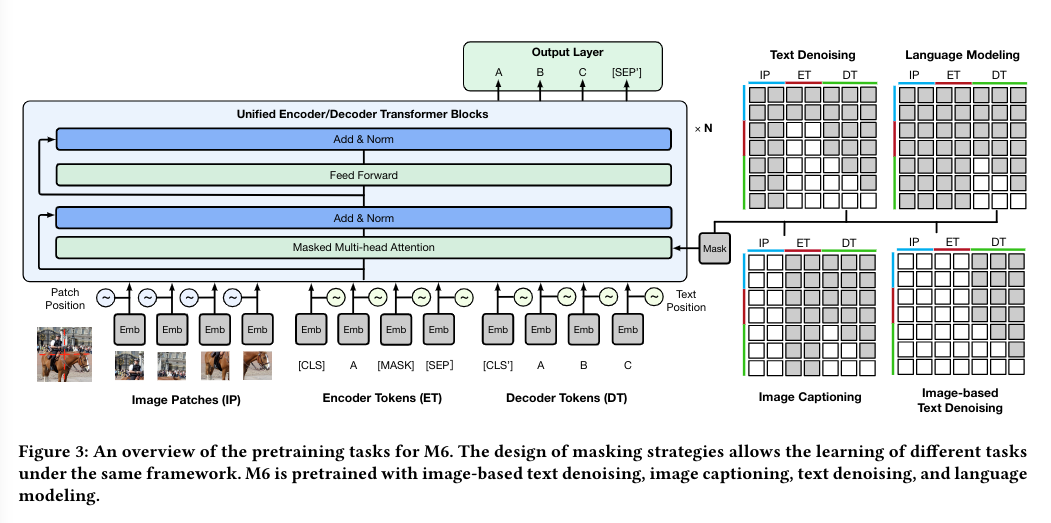
- they use masks to block cross attention between tokens so as to fit different types of downstream task
- Key idea: mask tokens during cross attention so as to solve certain tasks
Overview


Potential future work
Masking might be a good practice for multi-modal model.