[TOC]
- Title: BLIP2 - Boostrapping Language Image Pretraining 2023
- Author: Junnan Li et. al.
- Publish Year: 15 Jun 2023
- Review Date: Mon, Aug 28, 2023
- url: https://arxiv.org/pdf/2301.12597.pdf
Summary of paper
The paper titled “BLIP-2” proposes a new and efficient pre-training strategy for vision-and-language models. The cost of training such models has been increasingly prohibitive due to the large scale of the models. BLIP-2 aims to address this issue by leveraging off-the-shelf, pre-trained image encoders and large language models (LLMs) that are kept frozen during the pre-training process.
Key Components:
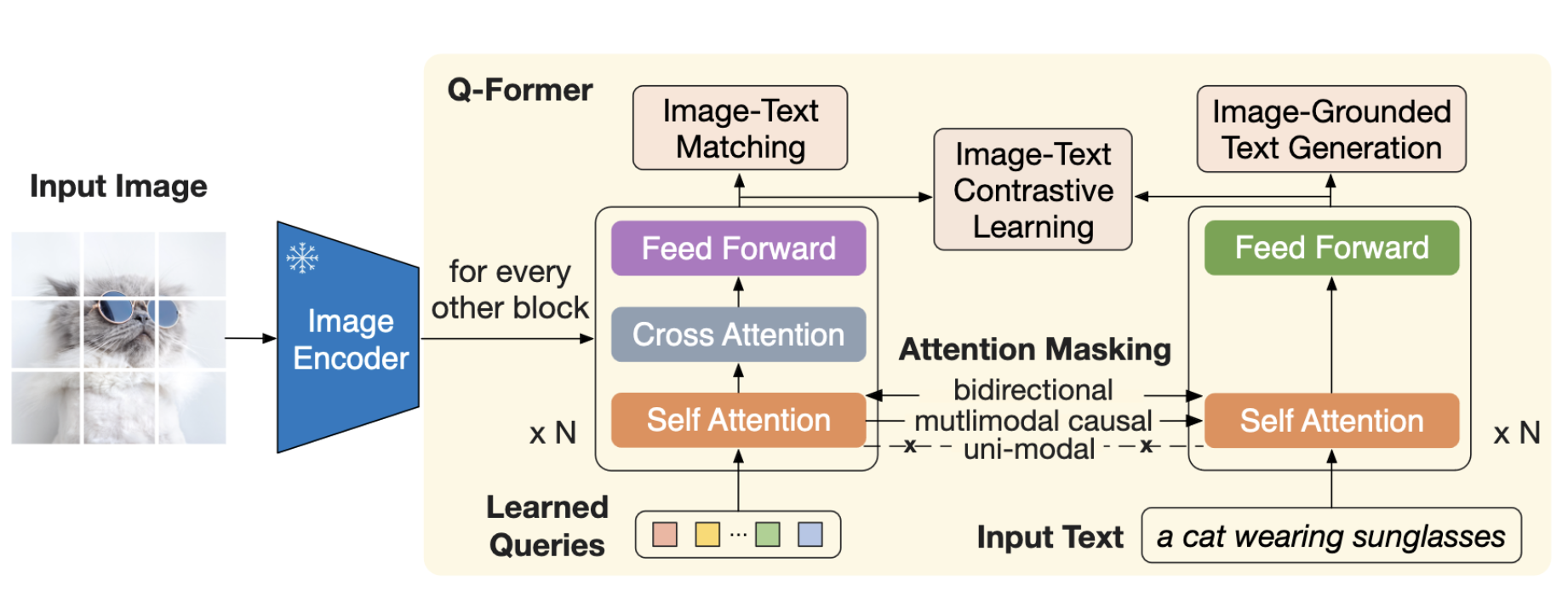
- Querying Transformer (Q-Former): A lightweight transformer that uses learnable query vectors to extract features from the frozen image encoder. It acts as an information bottleneck between the frozen image encoder and the frozen LLM.
- Two-Stage Pre-training Strategy:
- First Stage: Vision-language representation learning, where Q-Former learns to extract visual features most relevant to the text.
- Second Stage: Vision-to-language generative learning, where Q-Former is trained to produce visual representations that can be interpreted by the LLM.
Advantages:
- Efficiency: BLIP-2 has significantly fewer trainable parameters compared to existing methods but achieves state-of-the-art performance.
- Versatility: It performs well on various vision-language tasks like visual question answering, image captioning, and image-text retrieval.
- Zero-Shot Capabilities: Powered by LLMs, BLIP-2 can perform zero-shot image-to-text generation following natural language instructions.
The paper claims that BLIP-2 outperforms existing models like Flamingo80B by 8.7% on zero-shot VQAv2 while having 54x fewer trainable parameters.
Q-former
Information Bottleneck: The term “information bottleneck” refers to Q-Former’s role in selectively passing the most useful visual features from the frozen image encoder to the frozen LLM. It filters and condenses the information, ensuring that only the most relevant visual features are used for generating the desired text output.
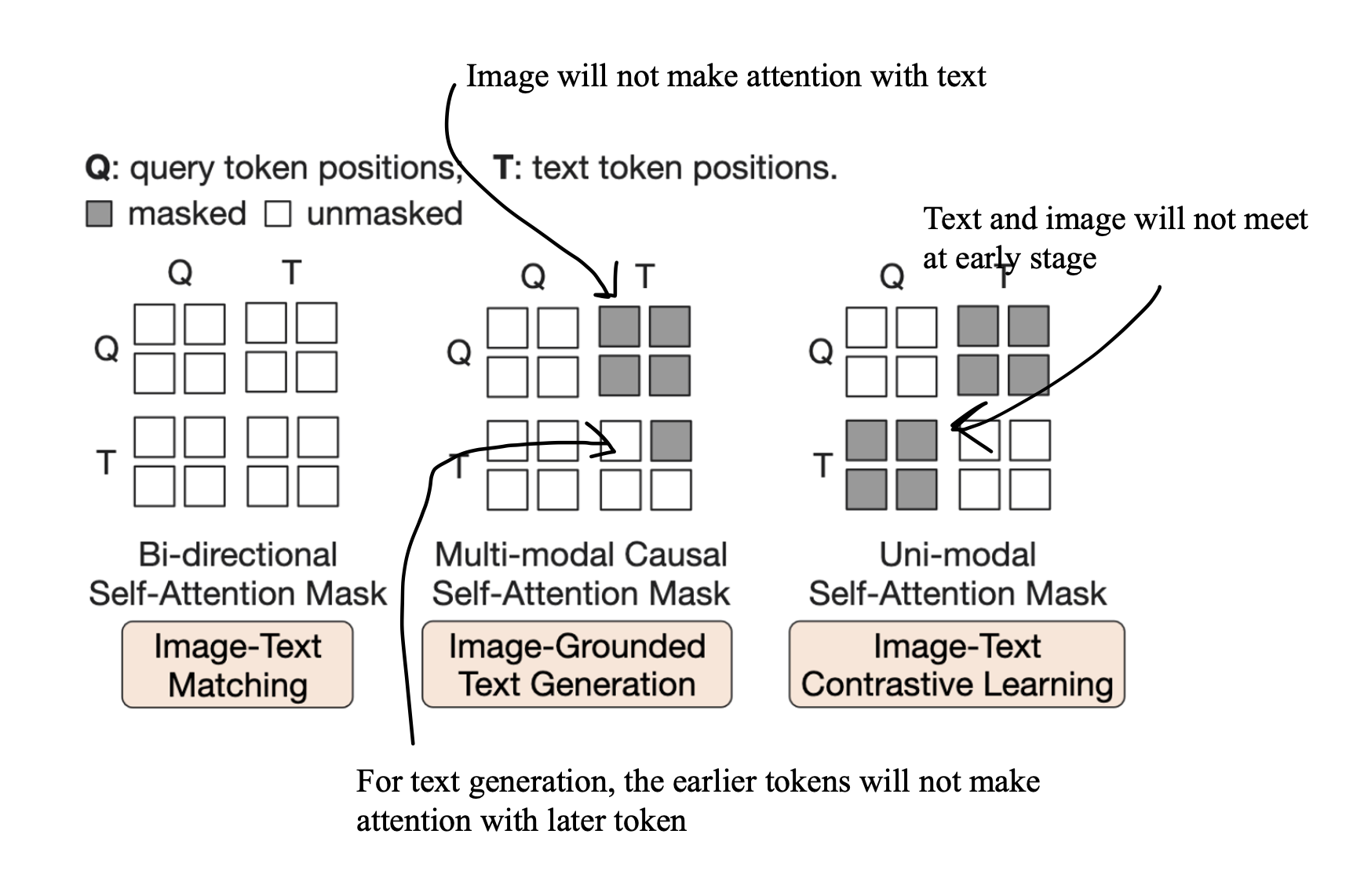
Learnable Query Embeddings: Q-Former employs a set of learnable query vectors (or embeddings) that serve as input to the image transformer. These queries interact with each other through self-attention layers and with frozen image features through cross-attention layers. They can also interact with the text.