[TOC]
- Title: BLIP Bootstrapping Language Image Pre Training for Unified Vision Language Understanding and Generation 2022
- Author: Junnan Li et. al.
- Publish Year: 15 Feb 2022
- Review Date: Mon, May 22, 2023
- url: https://arxiv.org/pdf/2201.12086.pdf
Summary of paper
Motivation
- performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision
Contribution
- BLIP effectively utilises the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones.
Some key terms
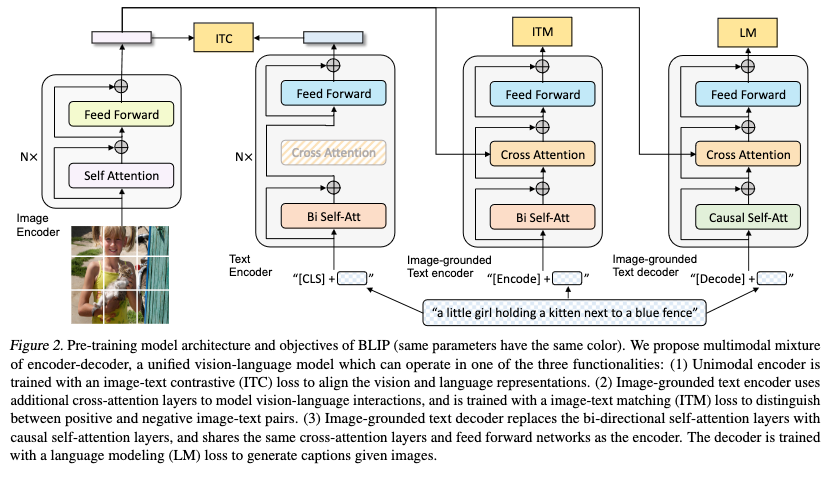
Architecture

CapFilt
- motivation: the al-texts often do not accurately describe the visual content of the images, making them a noisy signal that is suboptimal for learning vision-language alignment
- Specifically, the captioner is an image-grounded text decoder. It is finetuned with the LM objective to decode texts given images. Given the web images Iw, the captioner generates synthetic captions Ts with one caption per image. The filter is an image-grounded text encoder. It is finetuned with the ITC and ITM objectives to learn whether a text matches an image. The filter removes noisy texts in both the original web texts Tw and the synthetic texts Ts, where a text is considered to be noisy if the ITM head predicts it as unmatched to the image. Finally, we combine the filtered image-text pairs with the human-annotated pairs to form a new dataset, which we use to pre-train a new model.