[TOC]
- Title: Google Video Diffusion Models
- Author: Jonathan Ho et. al.
- Publish Year: 22 Jun 2022
- Review Date: Thu, Sep 22, 2022
Summary of paper
Motivation
- proposing a diffusion model for video generation that shows very promising initial results
Contribution
- this is the extension of image diffusion model
- they introduce a new conditional sampling technique for spatial and temporal video extension that performs better.
Some key terms
Diffusion model
- A diffusion model specified in continuous time is a generative model with latents

Training diffusion model
- learning to reverse the forward process for generation can be reduced to learning to denoise $z_t \sim q(z_t|x)$ into an estimate $\hat x_\theta (z_t, \lambda_t) \approx x$ for all $t$ (we will drop the dependence on $\lambda_t$) to simplify notation. We train this denoising model $\hat x_\theta$ using a weighted MSE loss
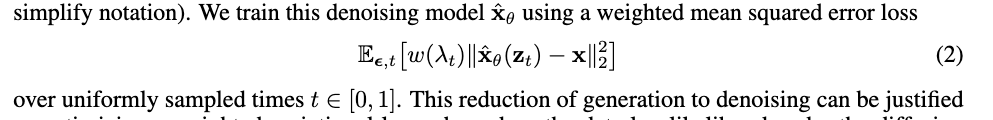
- this reduction of generation to denoising can be justified as optimising a weighted variational lower bound on the data log likelihood under the diffusion model.
Effective sampling with the new method for conditional generation – predictor-corrector sampler
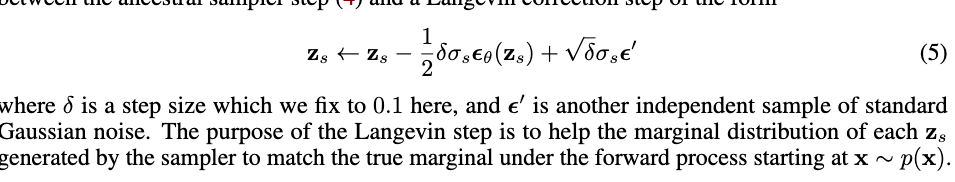
- in the conditional generation setting, the data $x$ is equipped with a conditional signal $c$, which may represent a text caption. To train a diffusion model to fit $p(x|c)$, the only modification that needs to be made is to provide $c$ to the model as $\hat x_\theta (z_t, c)$
Improvements to sample quality by classifier-free guidance

Video diffusion model
Architecture and condition
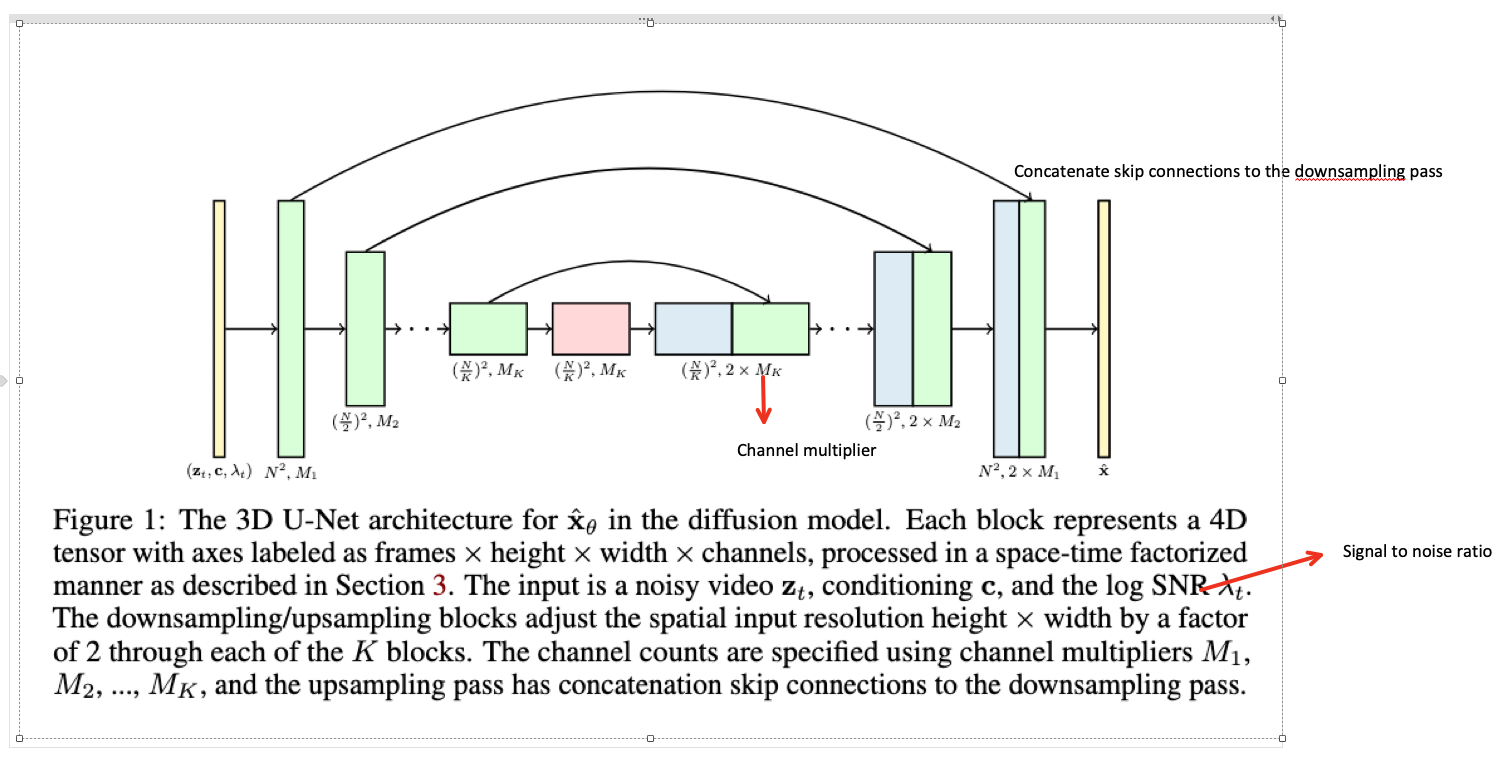
- the standard diffusion model is a U-Net
- which is a neural network architecture constructed as a spatial downsampling pass followed by a spatial upsampling pass with skip connections to the downsampling pass activations.
- The network is built from layer of 2D convolutional residual blocks, and each ConV block is followed by a spatial attention block.
- Conditioning information, such as $c$, is provided to the network in the form of an embedding vector (sentence embedding https://huggingface.co/sentence-transformers/clip-ViT-L-14), added into each residual block (they find it helpful to process these embedding vectors using several MLP layers before adding)
- For video data, we use a particular type of 3D U-Net that is factorised over space and time.
- space-only 3D convolution
- for instance, we change each 3x3 convolution into a 1x3x3 convolution (the first axis indexes video frames, the second and third index the spatial height and width)
- the attention in each spatial attention block remains as attention over space. (i.e., the first axis is treated as a batch axis)
- after each spatial attention block, we further insert a temporal attention block that perform attention over the first axis and treats the spatial axes as batch axes.
- this separation is good for computational efficiency
- space-only 3D convolution
Text-conditioned video generation
hyperparameters

Potential future work
Maybe we can also use this training method and architecture to pretrain our image-action-text multimodal model
we can combine this with the latent diffusion model to increase computational efficiency.