
[TOC]
- Title: Reinforcement Learning With Perturbed Rewards
- Author: Jingkang Wang et. al.
- Publish Year: 1 Feb 2020
- Review Date: Fri, Dec 16, 2022
Summary of paper
Motivation
- this paper studies RL with perturbed rewards, where a technical challenge is to revert the perturbation process so that the right policy is learned. Some experiments are used to support the algorithm (i.e., estimate the confusion matrix and revert) using existing techniques from the supervised learning (and crowdsourcing) literature.
- Limitation
- reviewers had concerns over the scope / significance of this work, mostly about how the confusion matrix is learned. If this matrix is known, correcting reward perturbation is easy, and standard RL can be applied to the corrected rewards.
- Specifically, the work seems to be limited in two substantial ways, both related to how confusion matrix is learned
- the reward function needs to be deterministic
- majority voting requires the number of states to be finite
- the significance of this work is therefore limited to finite-state problems with deterministic rewards, which is quite restricted.
- overall, the setting studied here, together with a thorough treatment of an (even restricted) case, could make an interesting paper that inspires future work. However, the exact problem setting is not completely clear in the paper, and the limitation of the technical contribution is somewhat unclear.
Contribution
- The SOTA PPO algorithm is able to obtain 84.6% and 80.8% improvements on average score for five Atari games, with error rates as 10% and 30% respectively
Some key terms
reward function is often perturbed
- it is difficult to design a reward function that produce credible rewards in the presence of noise. this is because the output from any reward function is subject to multiple kinds of randomness
- Inherent Noise, e.g., sensors on robot may report noisy observed rewards
- application specific noise, when an Rl agent receives feedback/instructions, different human instructor might provide drastically different feedback that leads to biased rewards (ref: Learning something from nothing: Leveraging implicit human feedback strategies)
- adversarial noise: reward poisoning attack is able to mislead pretrained RL policy arbitrarily.
arbitrary reward noise vs perturbed rewards
- arbitrary noise is just random, which is extremely challenging,
- perturbed rewards, where the observed rewards are learnable. the perturbed rewards are generated via a confusion matrix that flips the true reward to another one according to a certain distribution.
Unbiased estimator for true reward
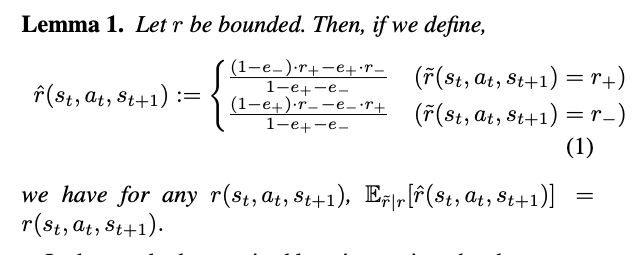
Potential future work
we can use the formulation in the paper